Texto faltante en la extracción de OCR
Problema
En algunos casos, el texto puede parecer estar faltante en la Vista de OCR, lo que impide que se extraiga utilizando la función de extracción.
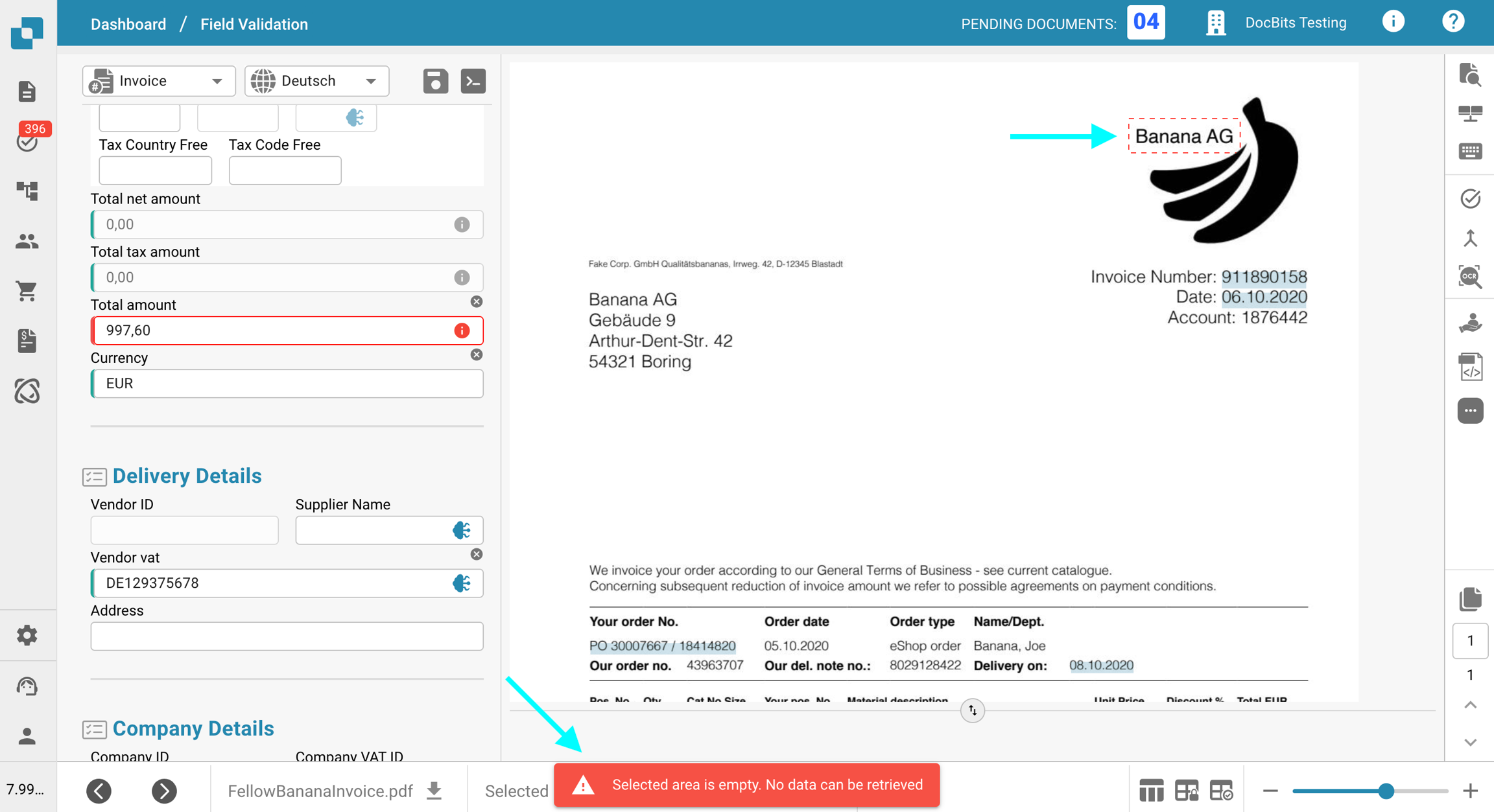
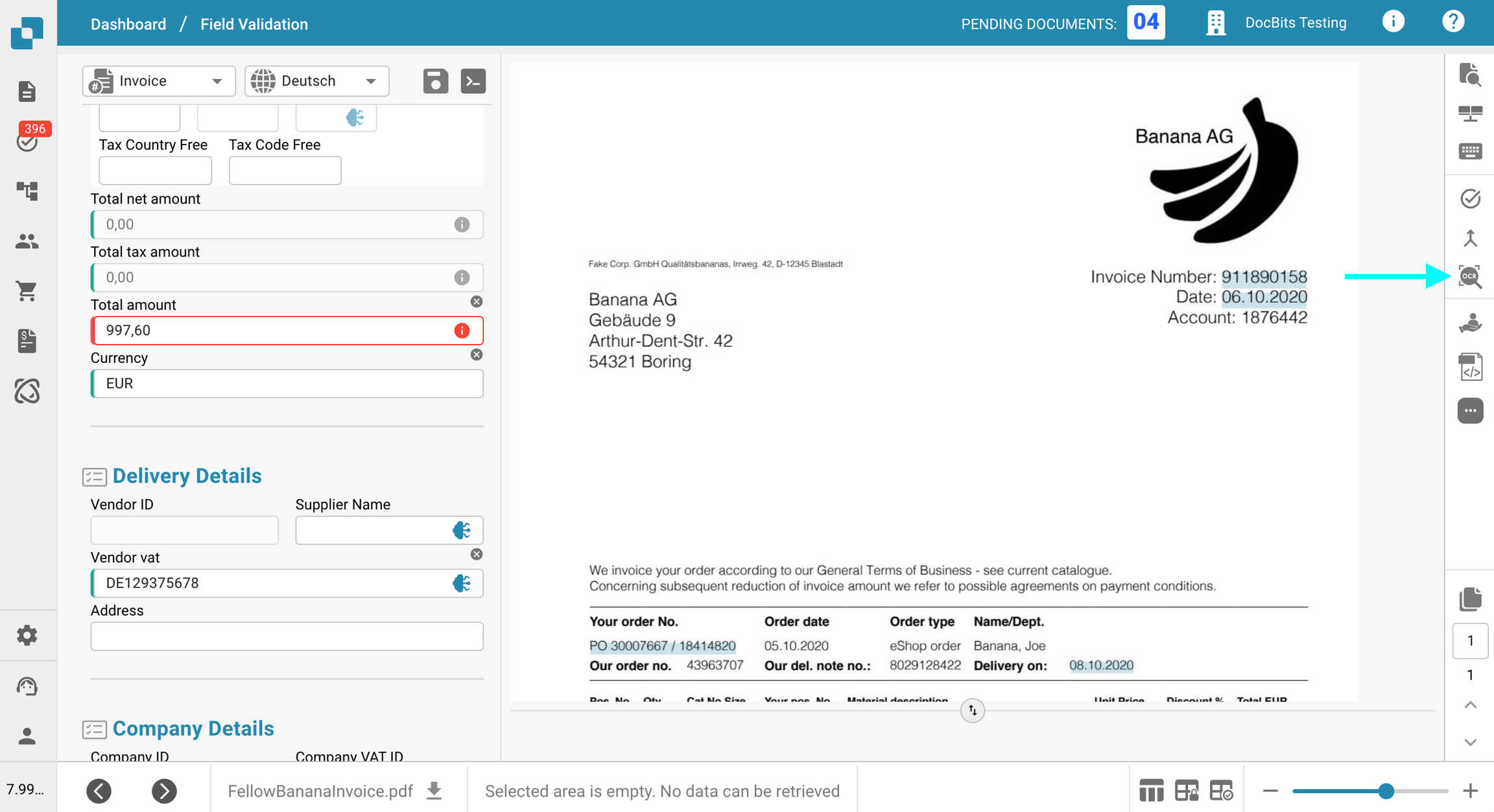
Para verificar esto, haga clic en el botón Vista de OCR en la barra de herramientas a la derecha. Si el texto no aparece allí, significa que no está disponible para la extracción.
Causa
La causa más probable es que el texto que está intentando extraer es parte de una imagen (por ejemplo, un logo o una sección escaneada) dentro del documento. Cuando la función E-Text está habilitada, el texto que aparece en imágenes o logos no se incluye en la capa de texto extraído. Como resultado, este texto no puede ser accedido o extraído a través de la lógica de extracción estándar.
Solución
Para resolver este problema, desactive la función E-Text—ya sea para el proveedor específico o para toda la organización. Una vez que E-Text esté desactivado, DocBits dependerá únicamente de OCR, que es capaz de extraer texto de imágenes y logos dentro del documento.
Desactivar E-Text para un Proveedor Específico
Abra un documento del proveedor específico en la Validación de Campo.
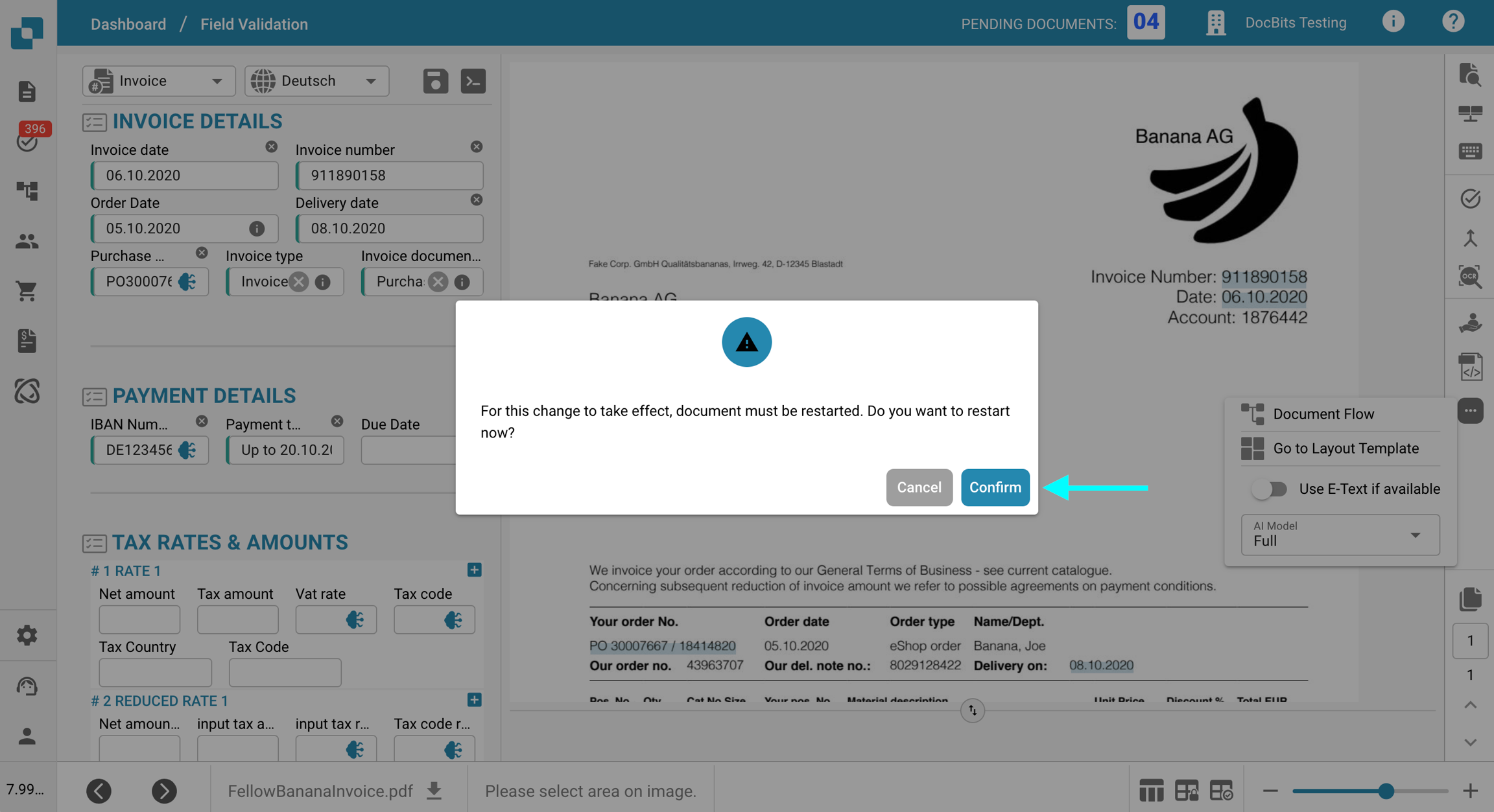
Haga clic en el menú de tres puntos en la barra de herramientas a la derecha.
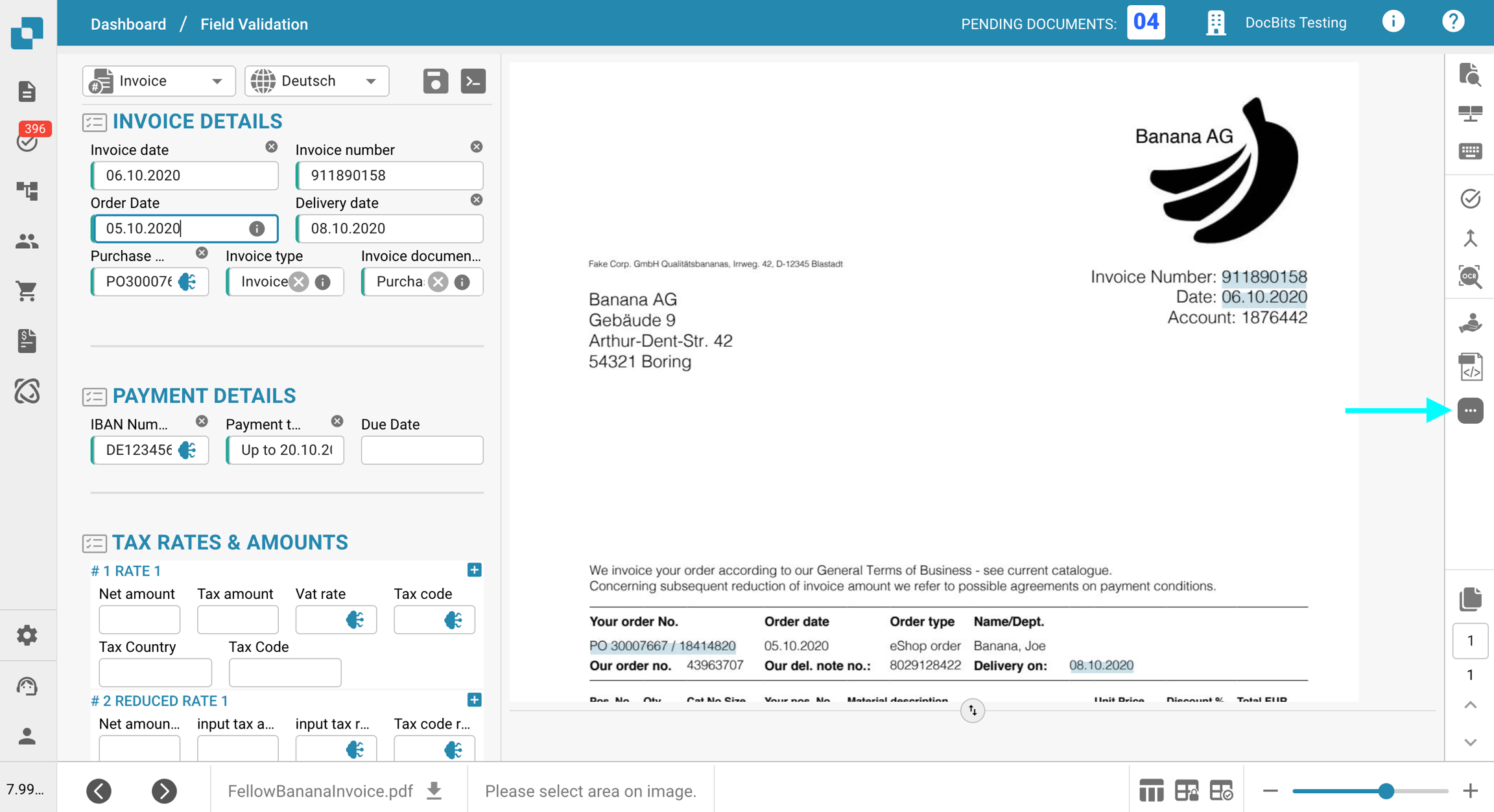
Desmarque Utilice E-Text si está disponible.
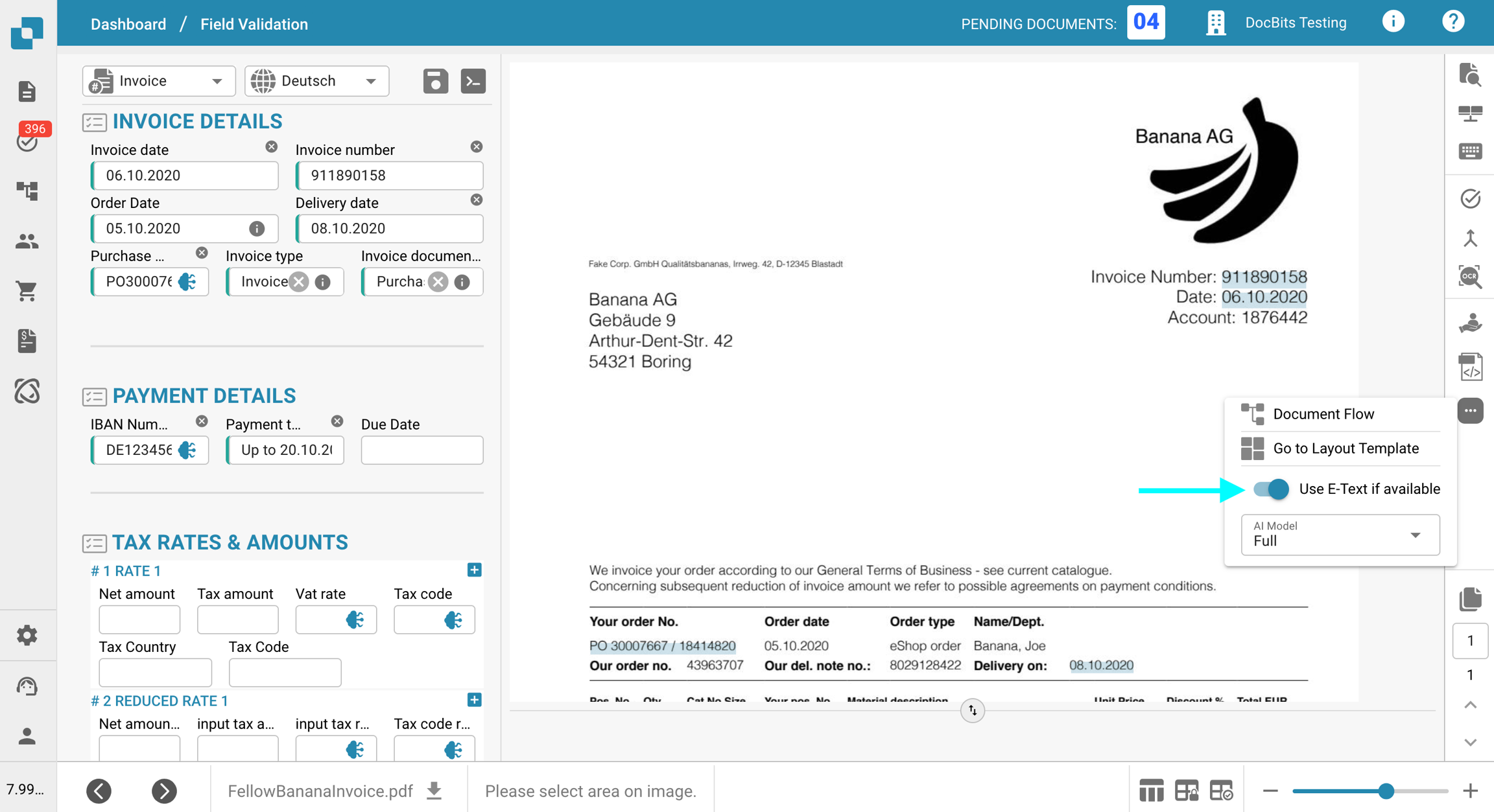
Haga clic en Confirmar para reiniciar el procesamiento del documento.
Desactivar E-Text para toda la Organización
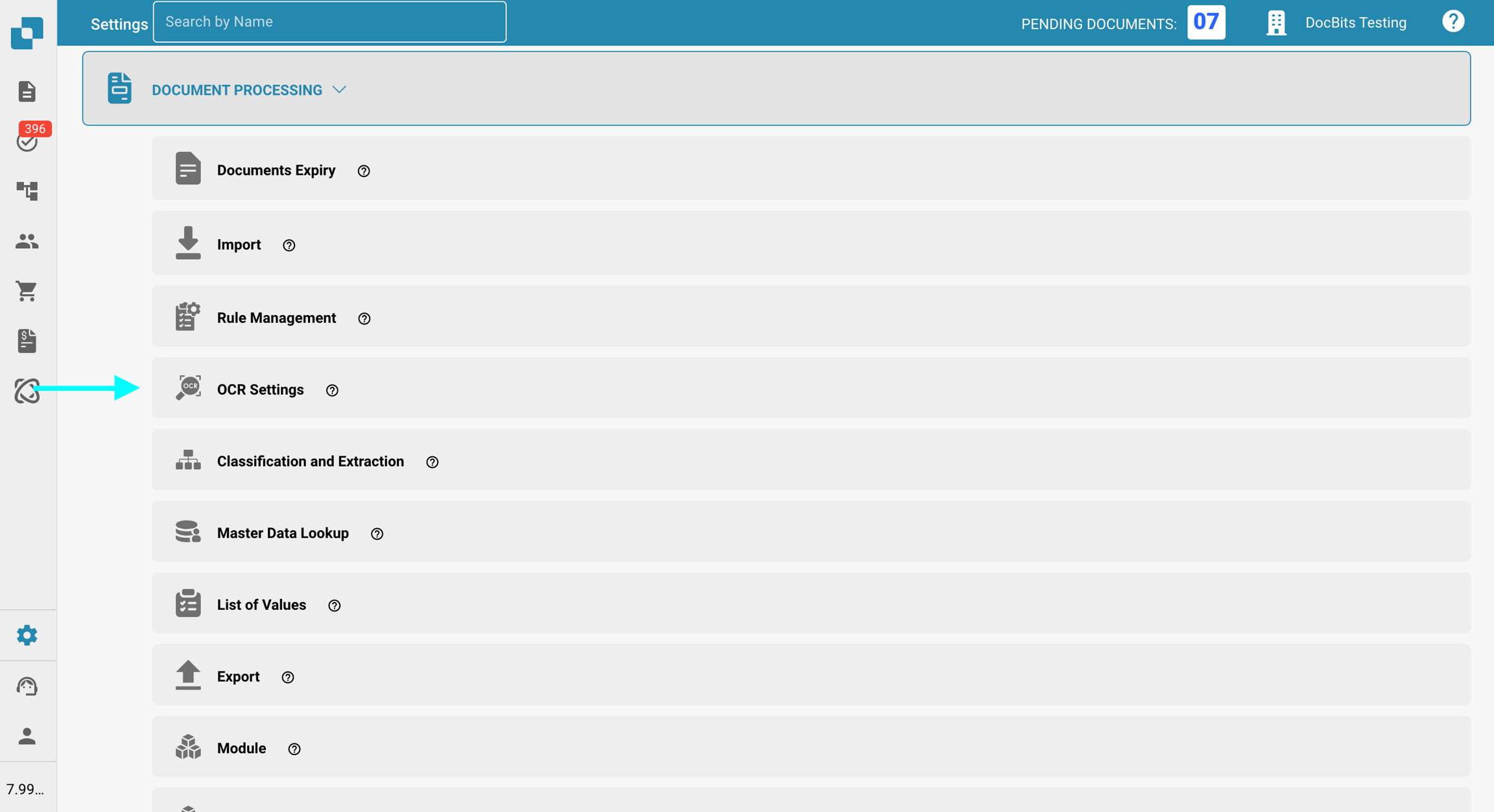
Vaya a Ajustes → Procesamiento de documentos → Configuración de OCR.
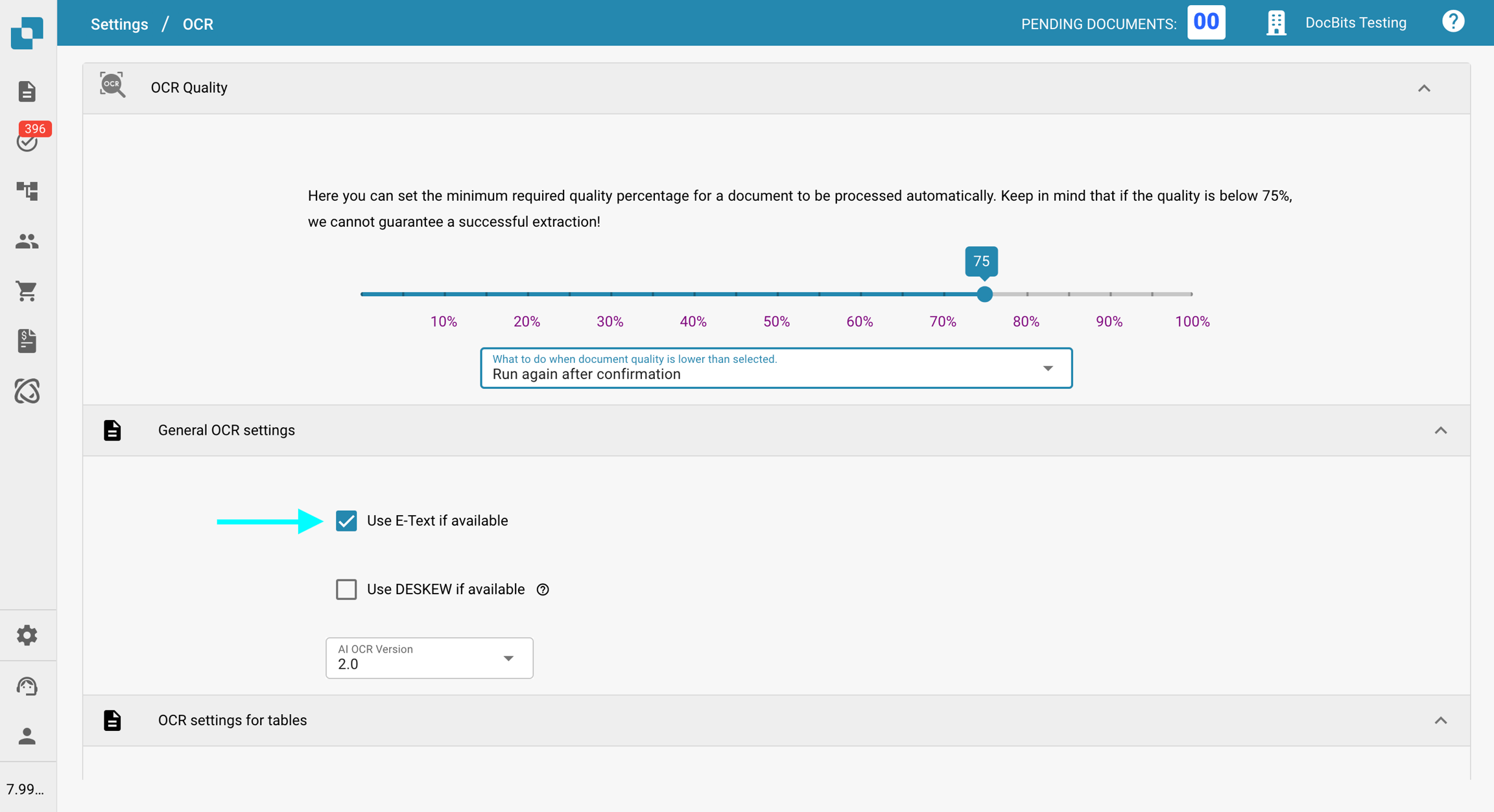
En Configuración general del OCR, desmarque la opción Utilice E-Text si está disponible.
Last updated
Was this helpful?