Classificatie en extractie
Overzicht
In de Instellingen voor Classificatie en extractie kun je:
Documenten splitsen inschakelen op basis van QR-codes
Bedrag opmaak configureren
Tabel extractie instellen
Verwerking van niet-ondersteunde ZUGFeRD-bestanden in- of uitschakelen
Speciale classificatieregels definiëren
Aangepast getrainde AI-modellen monitoren die in het classificatieproces worden gebruikt
Deze pagina biedt een gedetailleerde uitleg van alle beschikbare instellingen.
Toegang tot Instellingen voor Classificatie en extractie
Ga naar de Instellingen voor Classificatie en extractie via: Instellingen → Documentverwerking → Classificatie en extractie
Documenten splitsen
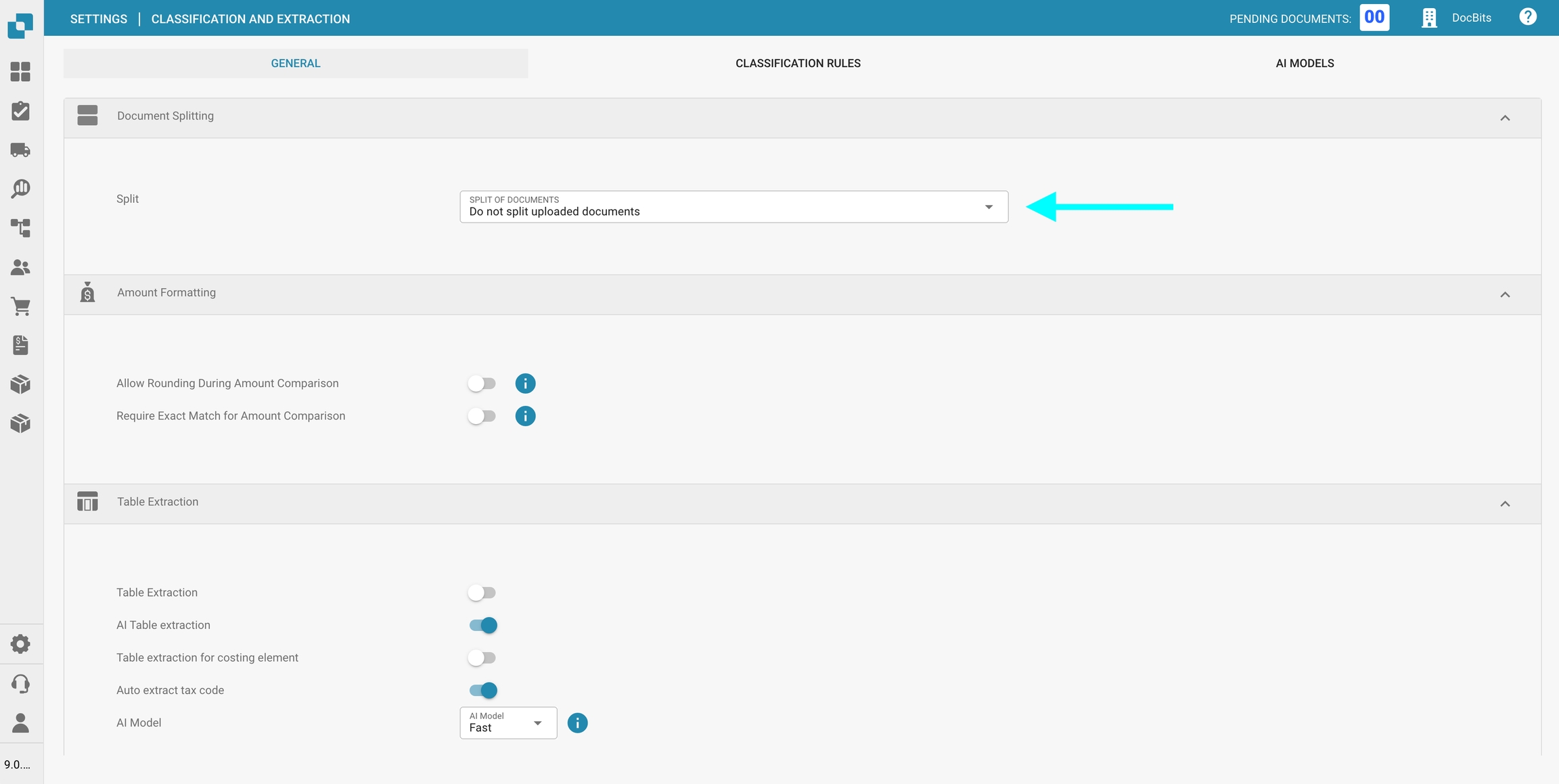
In de sectie Documenten splitsen kun je configureren of een geüpload document moet worden opgesplitst in meerdere documenten wanneer er een streepjescode op een van de pagina's verschijnt.
Om deze functie te activeren:
Ga naar de sectie Documenten splitsen.
Open het keuzemenu.
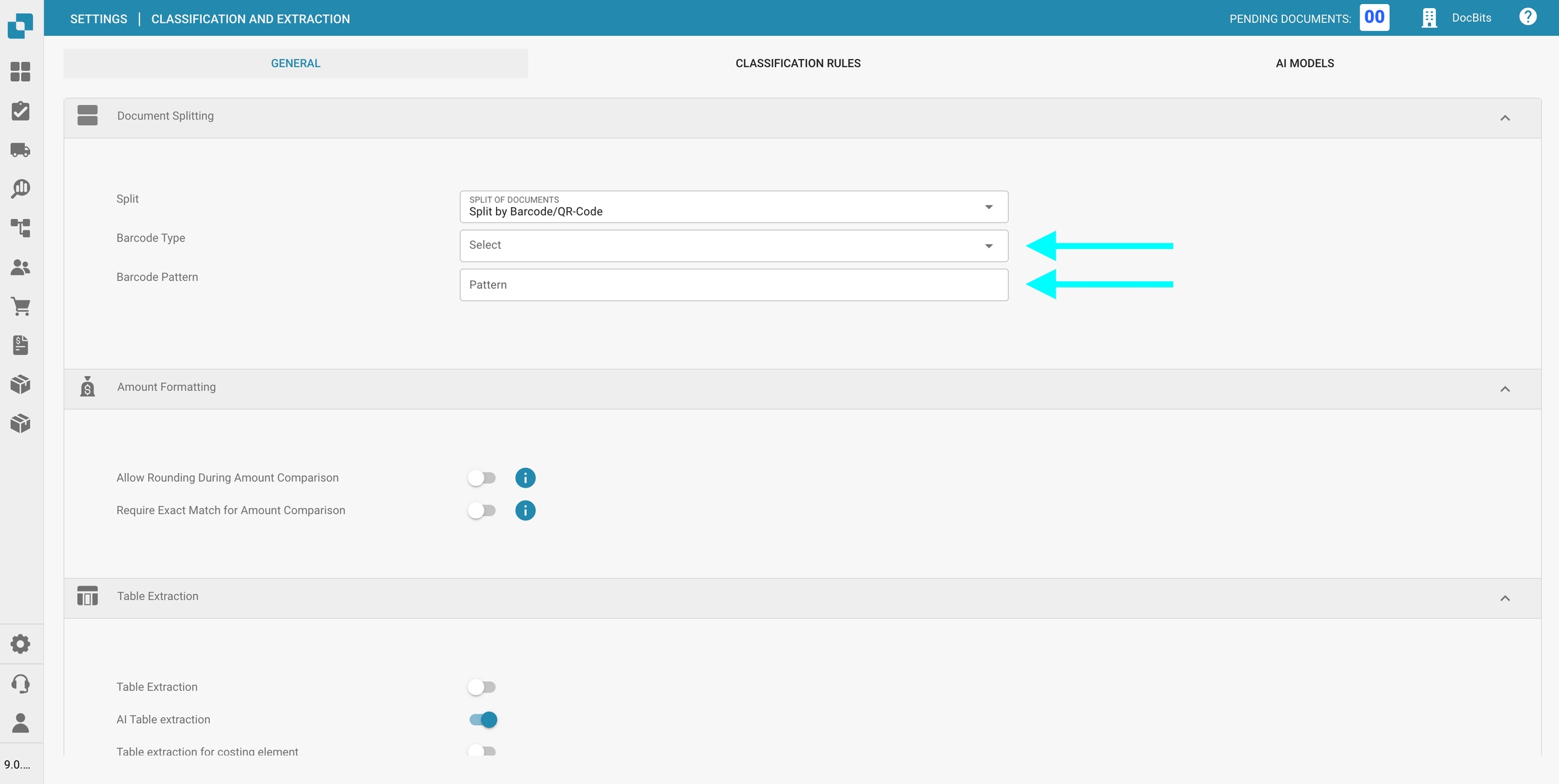
Selecteer Gesplitst op barcode/QR-code.
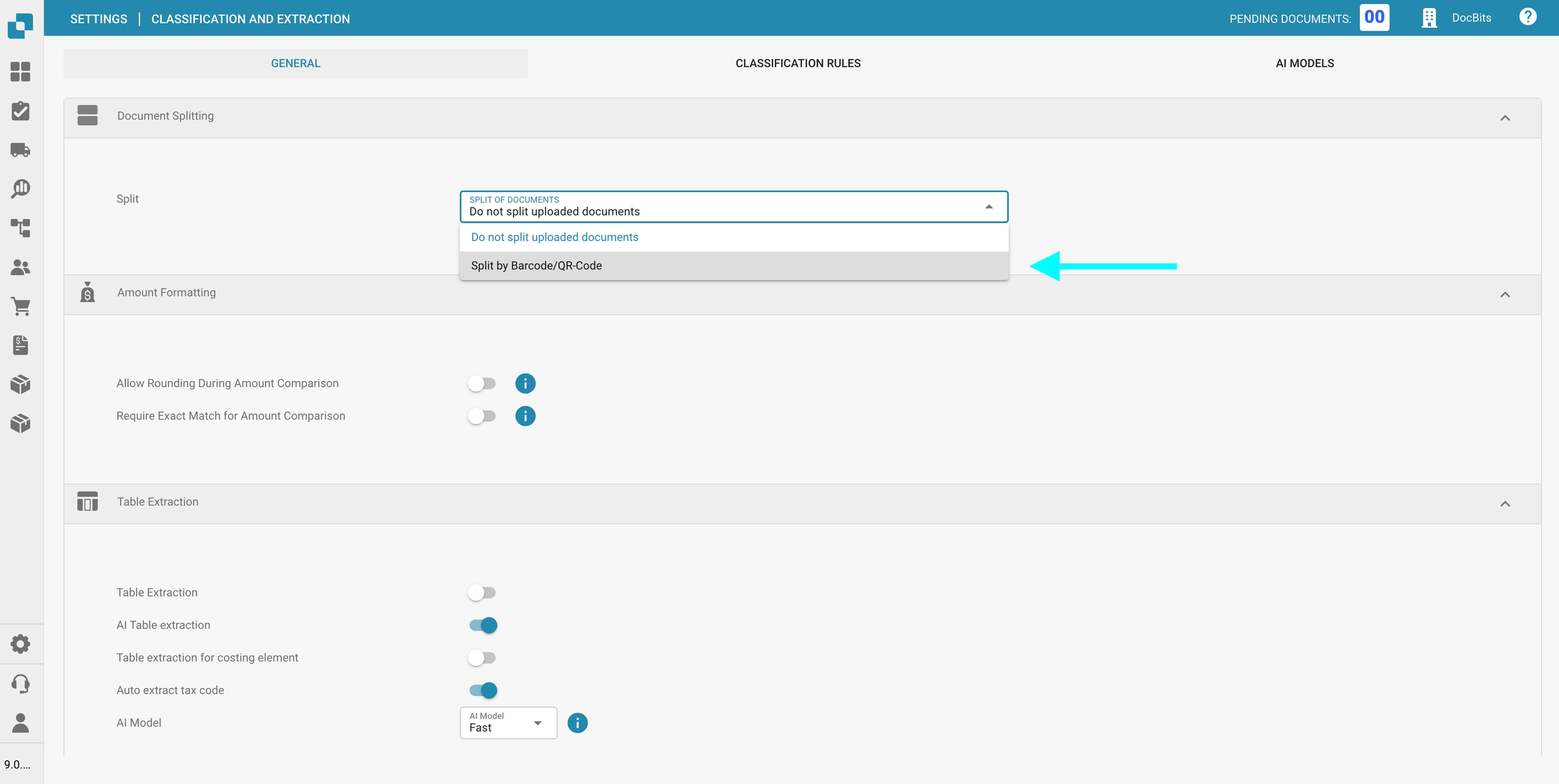
Je hebt vervolgens de optie om:
Een of meer streepjescode-typen te selecteren die moeten worden gedetecteerd.
Een regex-patroon op te geven waaraan de streepjescode moet voldoen om het splitsen van documenten te activeren.
Bedrag opmaak
In de sectie Bedrag opmaak heb je twee opties:
Afronding toestaan tijdens het vergelijken van bedragen: Indien ingeschakeld, is een tolerantie van ±0,5 toegestaan tijdens bedragvergelijking. Indien uitgeschakeld, geldt een standaardtolerantie van ±0,05.
Vereist exacte overeenkomst voor bedragvergelijking: Indien ingeschakeld, moeten bedragen exact overeenkomen met nul tolerantie. Indien uitgeschakeld, is een tolerantie van ±0,05 toegestaan.
Opmerking: Slechts één van deze instellingen kan tegelijk actief zijn.
Tabel extractie
Je kunt tabellen uit documenten extraheren door Tabel extractie of AI-tabel extractie in te schakelen. Een getrainde tabel—of deze nu AI-gebaseerd of handmatig is—wordt altijd gekoppeld aan een specifieke leverancier.
Tabel extractie: Activeert handmatige tabel extractie. Tabellen moeten handmatig worden getraind. Meer informatie over handmatige training vind je hier.
AI-tabel extractie: Gebruikt AI om tabellen automatisch te extraheren. Als de resultaten niet nauwkeurig genoeg zijn, wordt aanbevolen om over te schakelen naar handmatige Tabel extractie voor meer controle en training.
Tabelextractie voor kostenelement: Wanneer ingeschakeld, kan DocBits kostenelementen uit tabellen op regelniveau extraheren en deze dienovereenkomstig classificeren. Een gedetailleerde uitleg is beschikbaar hier.
Automatisch belastingcode ophalen: Wanneer ingeschakeld, vult het systeem automatisch het veld Belastingcode op het Validatiescherm—mits er een belastingcodeveld is geconfigureerd. Meer informatie over deze instelling vind je hier.
AI-model: Hiermee kun je specificeren welk AI-model wordt gebruikt voor tabelextractie. Je ziet ook een tabel met:
Welke Leveranciers welk AI-model gebruiken
Of ze E-Text gebruiken
Opties om een item te verwijderen of de trainingsgegevens te resetten
Deze instelling wordt in detail uitgelegd hier.
Elektronisch document
Proces Niet-ondersteund ZUGFeRD PDF: Indien ingeschakeld, worden niet-ondersteunde ZUGFeRD-versies verwerkt als standaard-pdf's en wordt de ingesloten XML genegeerd.
De lijst met ondersteunde ZUGFeRD-versies vind je hier.
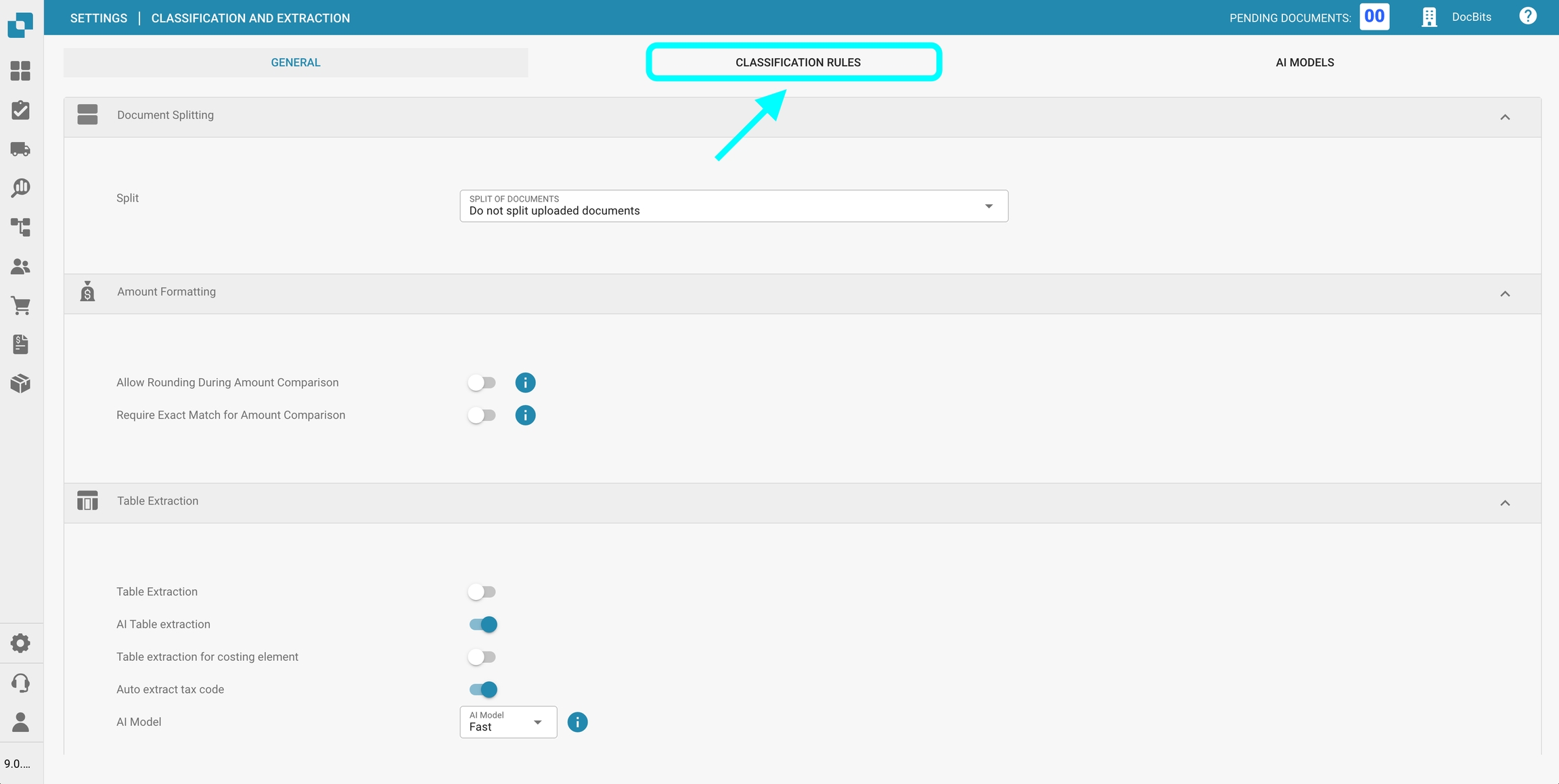
Classificatieregels
In de sectie Classificatieregels kun je specifieke regex-patronen en criteria definiëren om het systeem te helpen documenten automatisch te classificeren tijdens de verwerking.
Om deze sectie te openen, klik op het tabblad Classificatieregels bovenaan de pagina.
Nieuwe classificatieregel toevoegen
Om een nieuwe regel te maken:
Klik rechtsboven op Toevoegen.
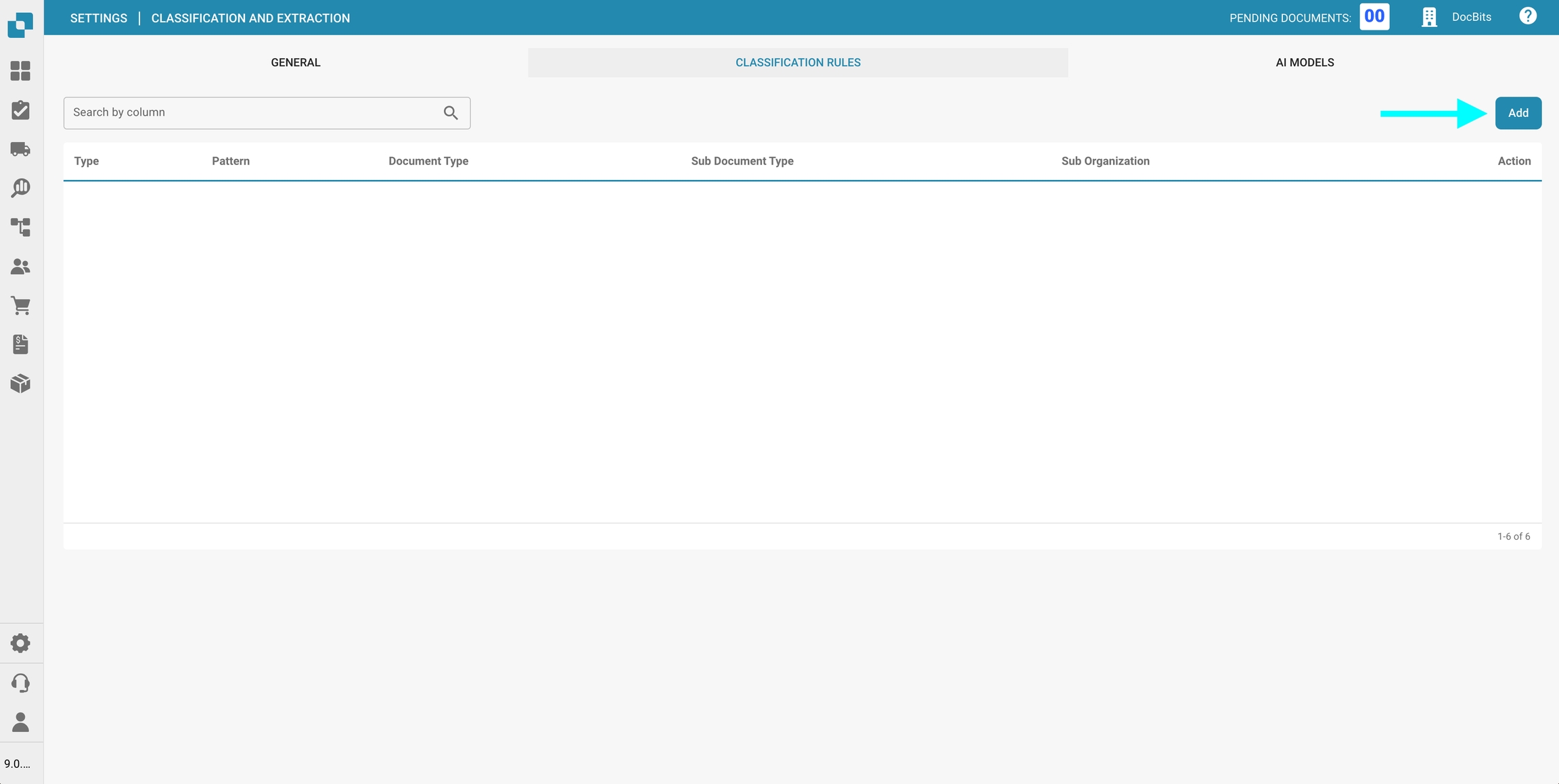
Vul de volgende velden in:
Patroon: Het regex-patroon waar het systeem naar moet zoeken om classificatie te activeren.
Type: Waar naar het patroon moet worden gezocht (bijv. Streepjescode).
Suborganisatie (optioneel): Geef aan op welke suborganisatie de regel van toepassing is.
Documenttype: Definieer het documenttype dat moet worden toegewezen wanneer het patroon overeenkomt.
Subdocumenttype (optioneel): Geef een subtype op voor een gedetailleerdere classificatie.
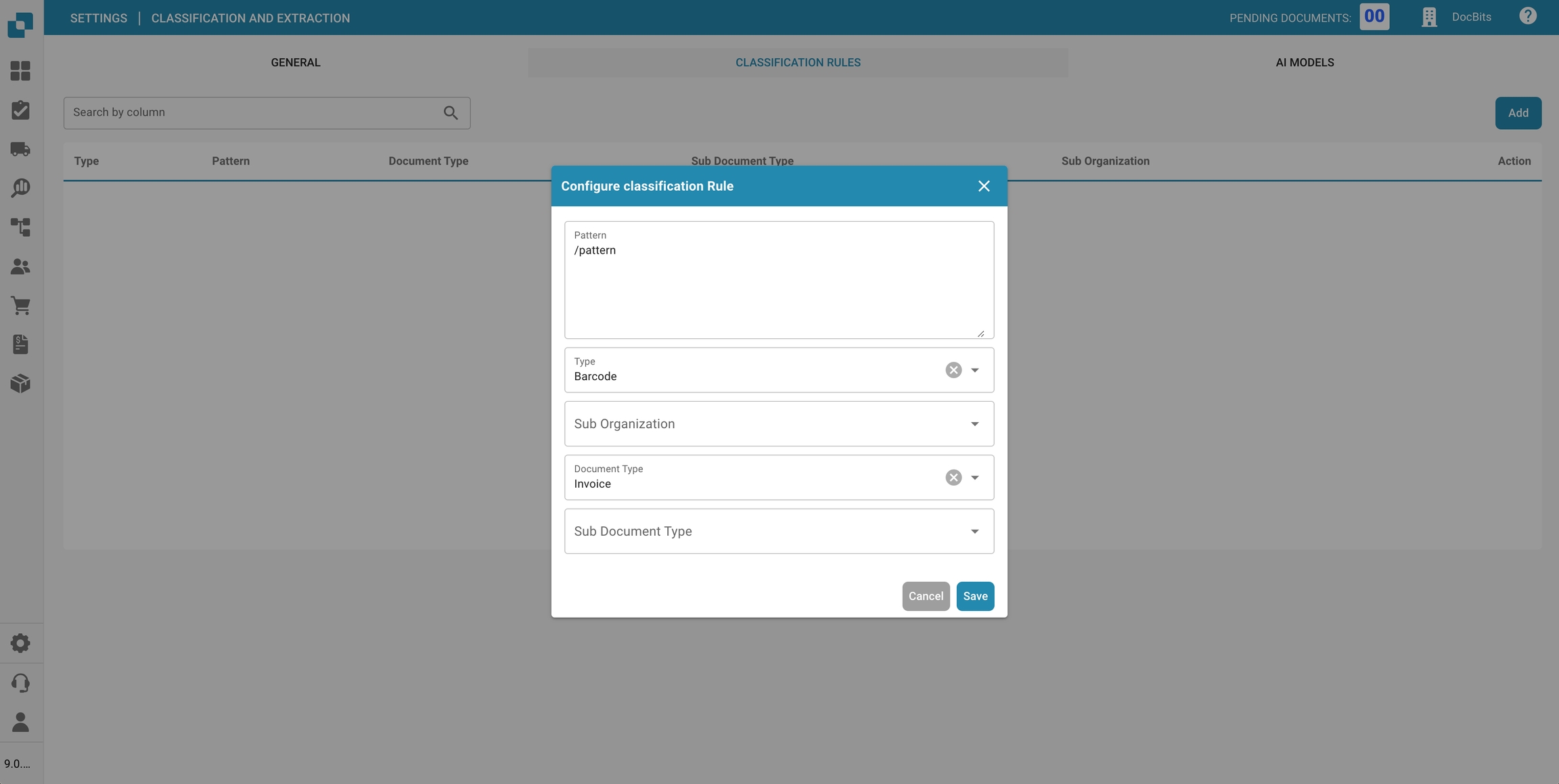
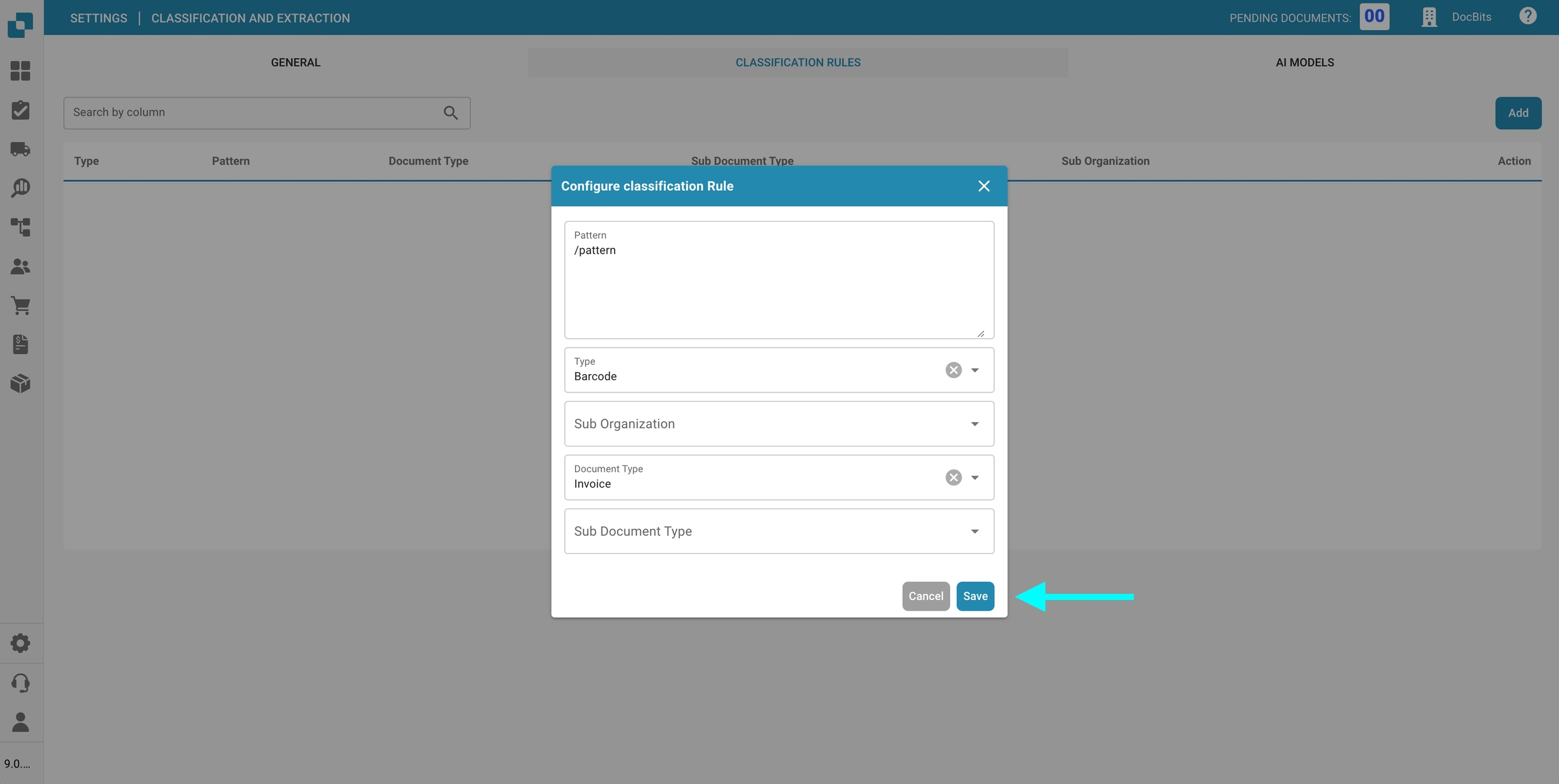
Klik op Opslaan om je classificatieregel op te slaan.
Een classificatieregel bewerken
Om een bestaande regel te bewerken:
Klik op de drie puntjes in de kolom Acties.
Selecteer Bewerking.
Breng de gewenste wijzigingen aan.
Klik op Opslaan om de updates toe te passen.
Een classificatieregel verwijderen
Om een regel te verwijderen:
Klik op de drie puntjes in de kolom Acties.
Selecteer Verwijderen.
AI-modellen
De sectie AI-modellen toont alle op maat getrainde modellen die specifiek voor jouw behoeften zijn verfijnd.
Toegang tot de sectie AI-modellen
Om deze sectie te openen, klik op het tabblad AI-modellen bovenaan de pagina.
Modelcategorieën
Modellen zijn georganiseerd in categorieën. Onder elke categorienaam wordt het aantal modellen weergegeven dat deze bevat. Klik op een categorie om de details te bekijken.
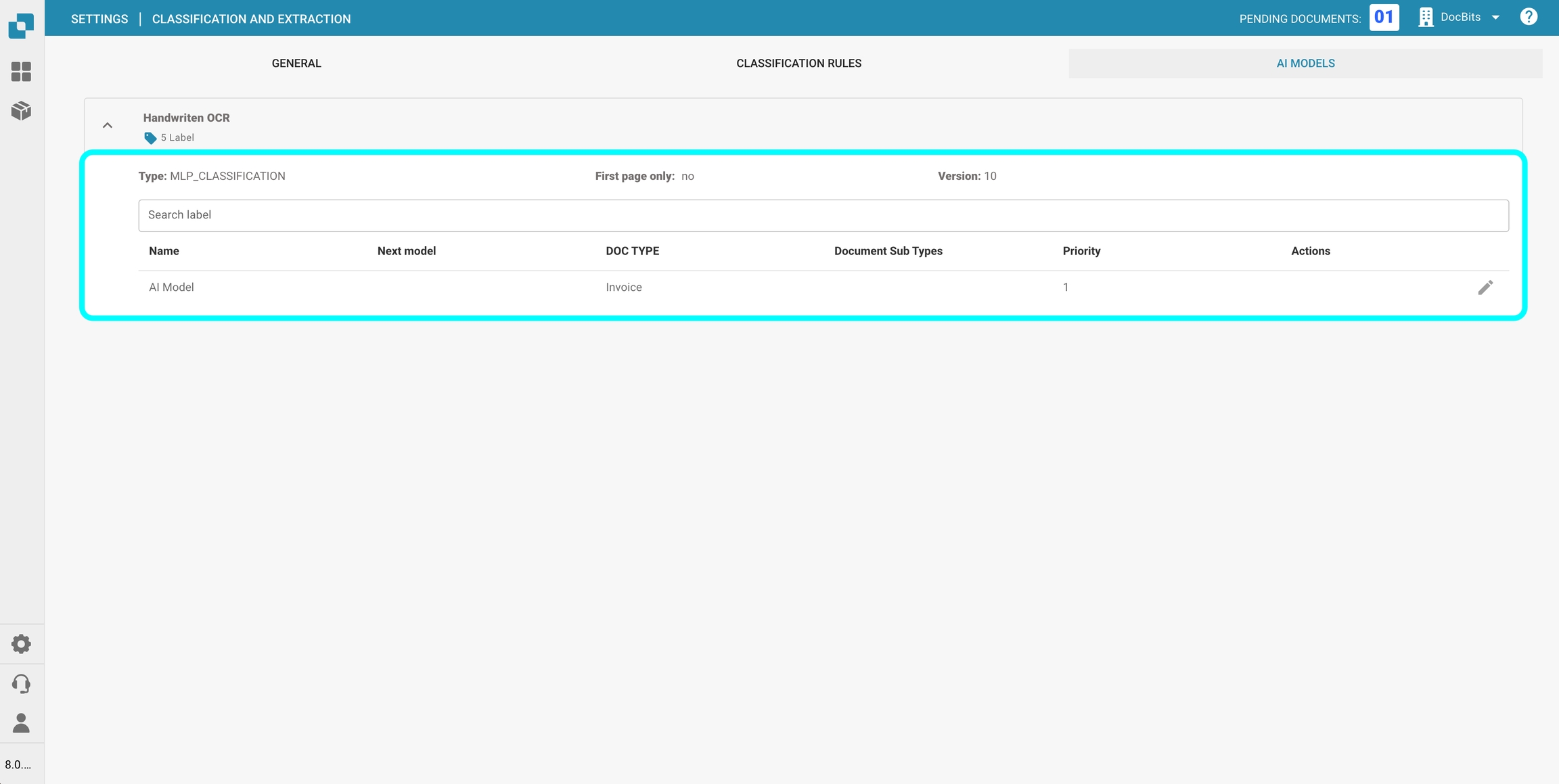
Bovenaan de pagina van de geselecteerde categorie zie je kerninformatie over elk model:
Type: Het type model.
Alleen eerste pagina: Geeft aan of het model alleen de eerste pagina van een document verwerkt.
Versie: Het versienummer van het model.
Modeltabel
Alle modellen binnen een categorie worden weergegeven in een tabel met de volgende informatie:
Naam: De naam van het model.
Volgend model: Het model dat de output van het huidige model verder zal verwerken.
Documenttype: Het primaire documenttype dat door het model tijdens classificatie wordt toegewezen.
Document-subtypen: De subtypen waarin het document verder wordt geclassificeerd.
Prioriteit: Het prioriteitsniveau dat de positie van het model in de classificatiewachtrij bepaalt.
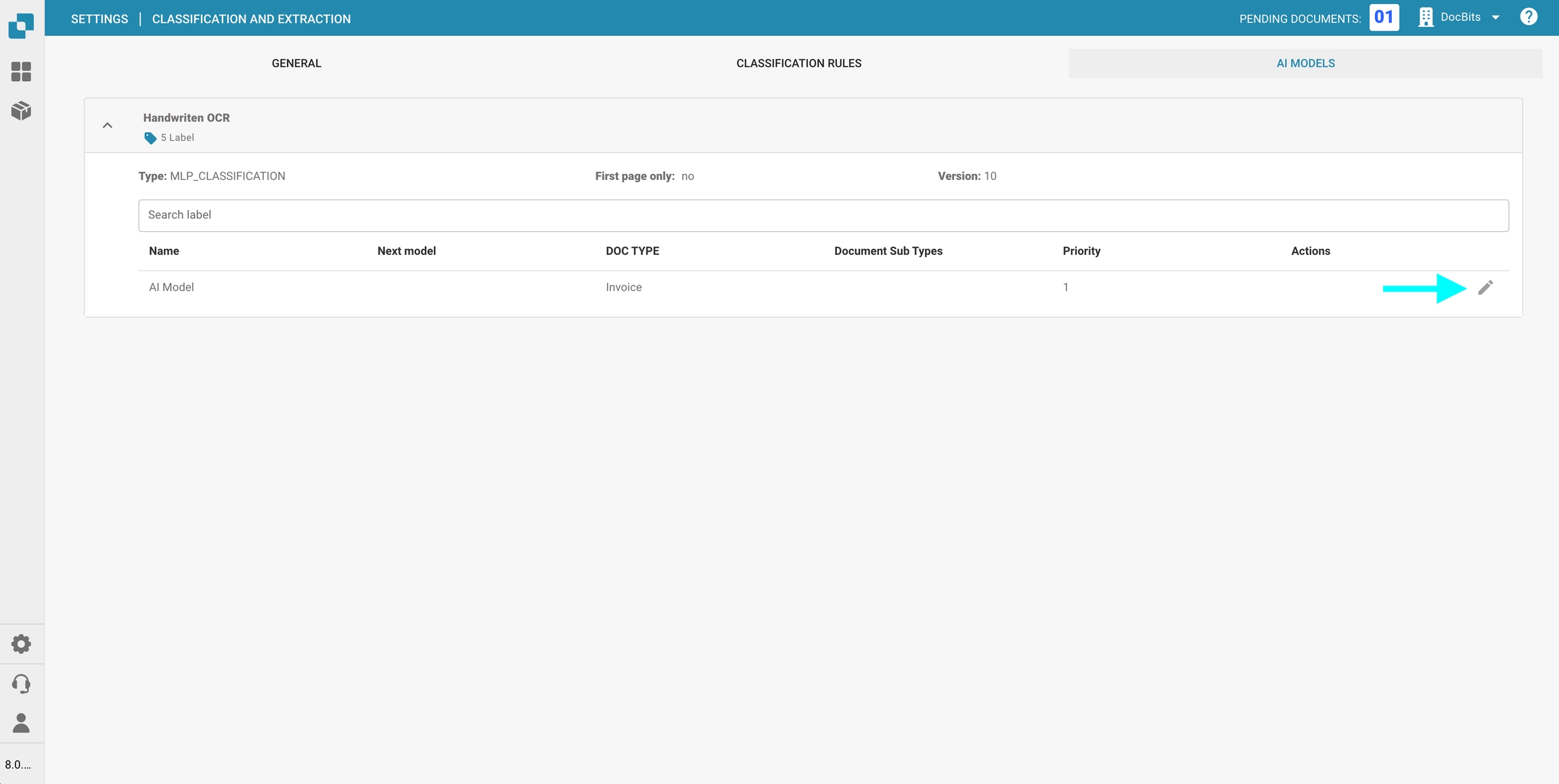
Een model bewerken
Om een model te bewerken:
Klik op het penpictogram in de kolom Acties naast het model dat je wilt bewerken.
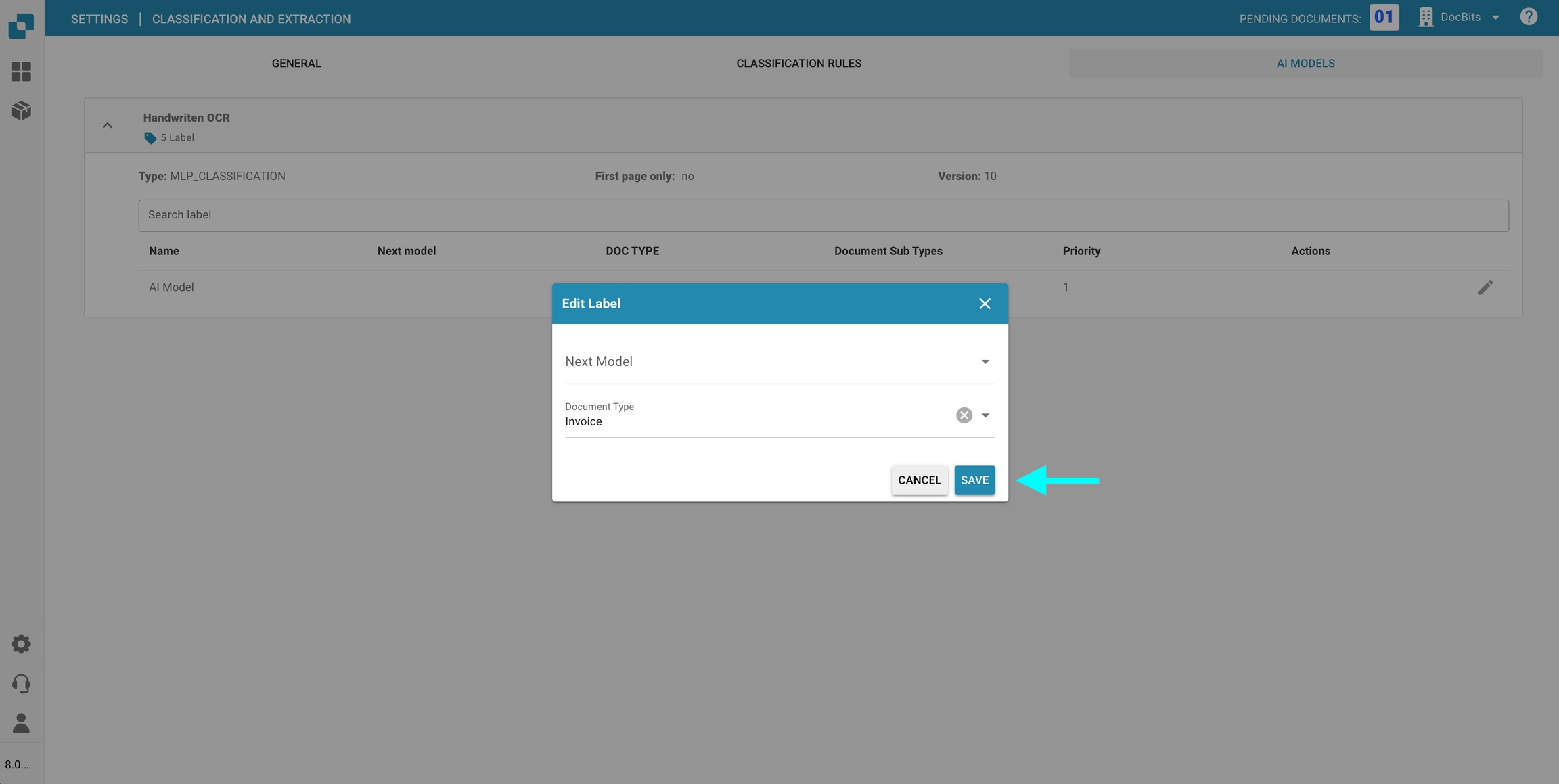
Werk de beschikbare velden bij:
Volgend model: Selecteer het model dat de output van het huidige model moet verwerken.
Documenttype: Kies het documenttype waarmee het model de input moet classificeren.
Klik op Opslaan om je wijzigingen toe te passen.
Last updated
Was this helpful?