Fehlender Text in der OCR-Extraktion
Problem
In einigen Fällen kann es vorkommen, dass Text in der OCR-Ansicht zu fehlen scheint, was die Extraktion mit der Extraktionsfunktion verhindert.
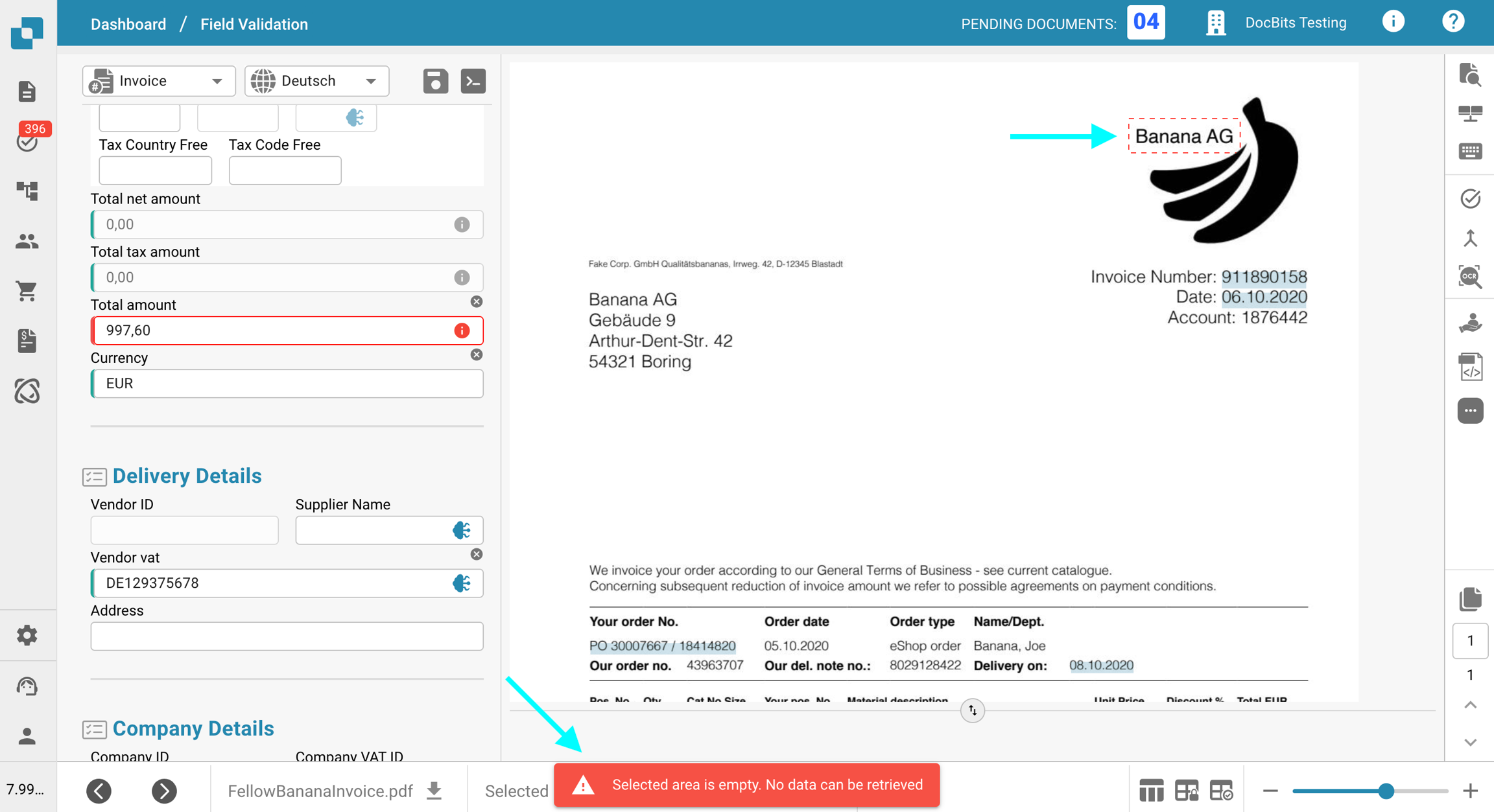
Um dies zu überprüfen, klicken Sie auf die Schaltfläche OCR-Ansicht in der Symbolleiste auf der rechten Seite. Wenn der Text dort nicht angezeigt wird, bedeutet dies, dass er nicht für die Extraktion verfügbar ist.
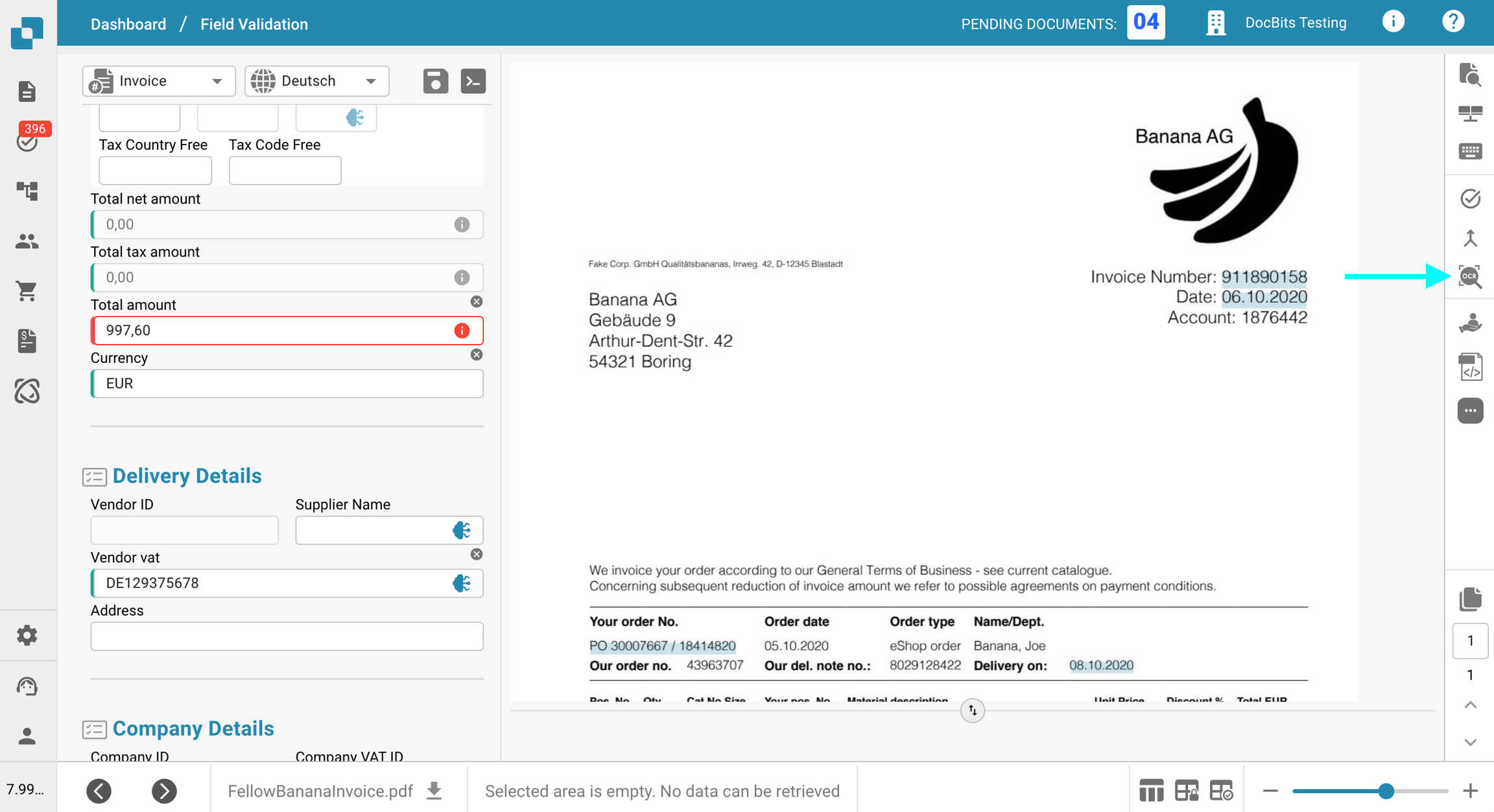
Ursache
Die wahrscheinlichste Ursache ist, dass der Text, den Sie extrahieren möchten, Teil eines Bildes (z. B. eines Logos oder eines gescannten Abschnitts) innerhalb des Dokuments ist. Wenn die E-Text-Funktion aktiviert ist, wird Text, der auf Bildern oder Logos erscheint, nicht in die extrahierte Textebene aufgenommen. Daher kann dieser Text nicht über die standardmäßige Extraktionslogik zugegriffen oder extrahiert werden.
Lösung
Um dieses Problem zu beheben, deaktivieren Sie die E-Text-Funktion—entweder für den spezifischen Anbieter oder für die gesamte Organisation. Sobald E-Text deaktiviert ist, wird DocBits ausschließlich auf OCR angewiesen sein, das in der Lage ist, Text aus Bildern und Logos innerhalb des Dokuments zu extrahieren.
E-Text für einen bestimmten Anbieter deaktivieren
Öffnen Sie ein Dokument vom spezifischen Anbieter in der Feldvalidierung.
Klicken Sie auf das Drei-Punkte-Menü in der Symbolleiste auf der rechten Seite.
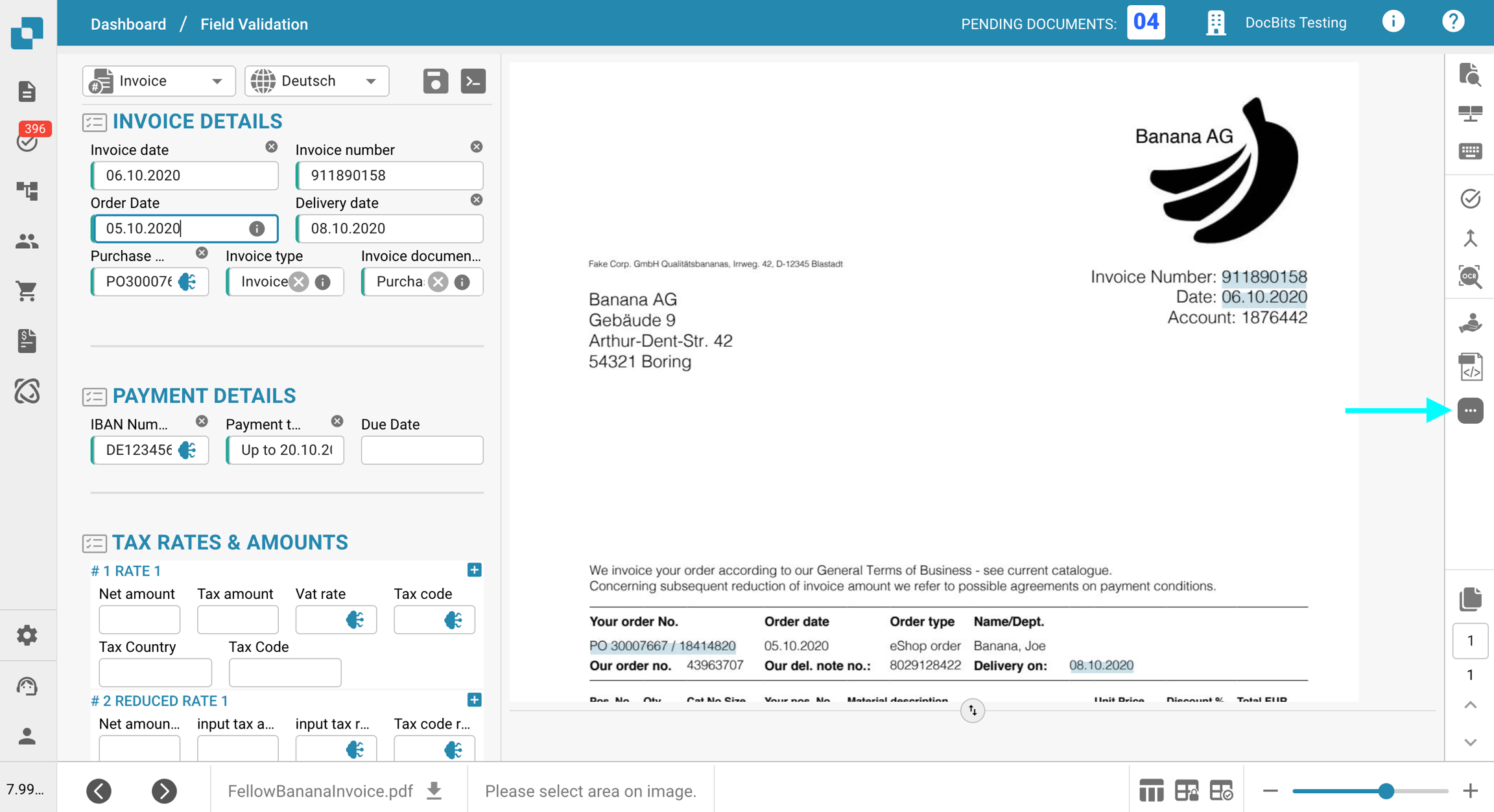
Deaktivieren Sie die Option E-Text verwenden, falls verfügbar.
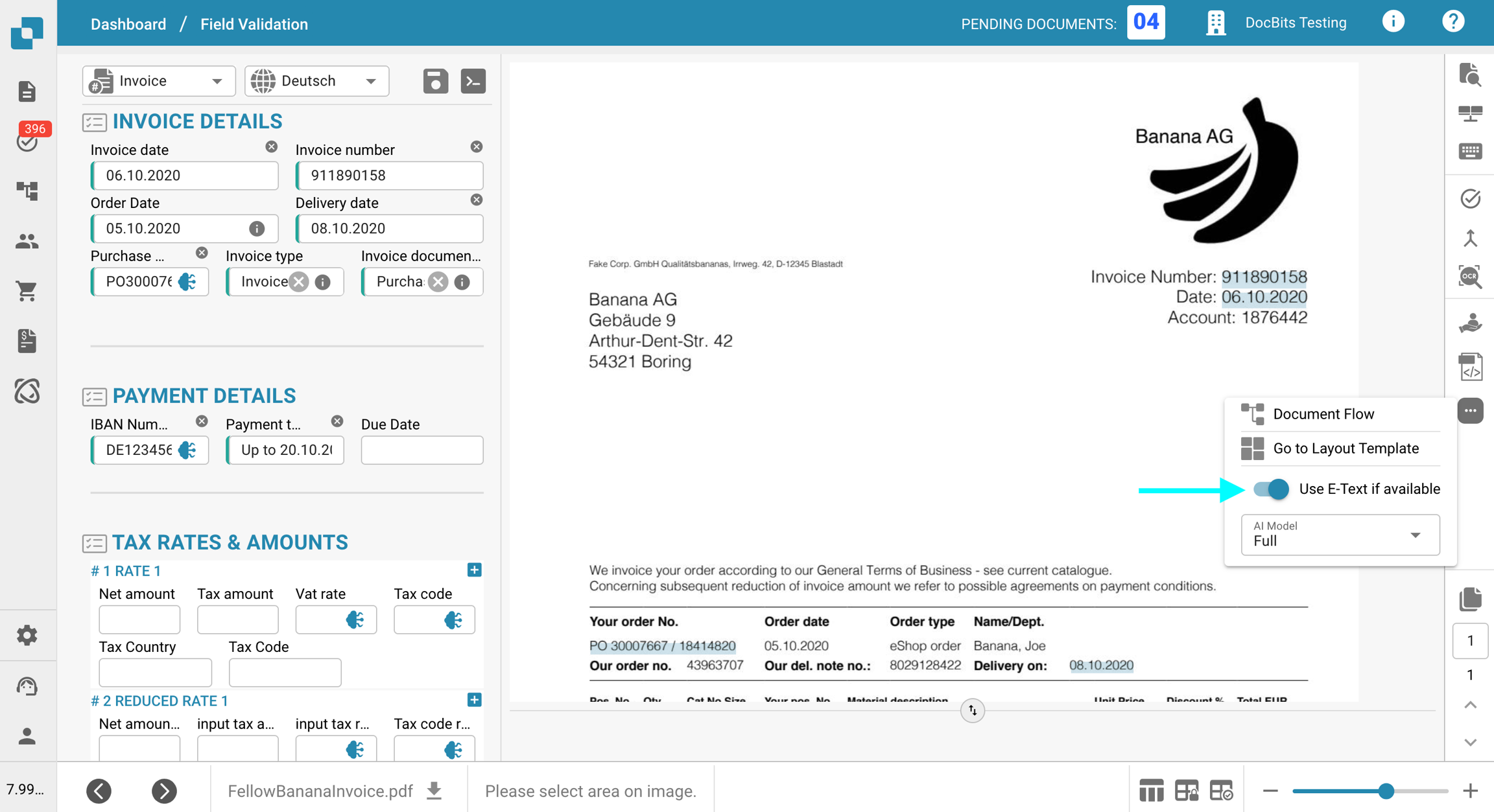
Klicken Sie auf Bestätigen, um die Verarbeitung für das Dokument neu zu starten.
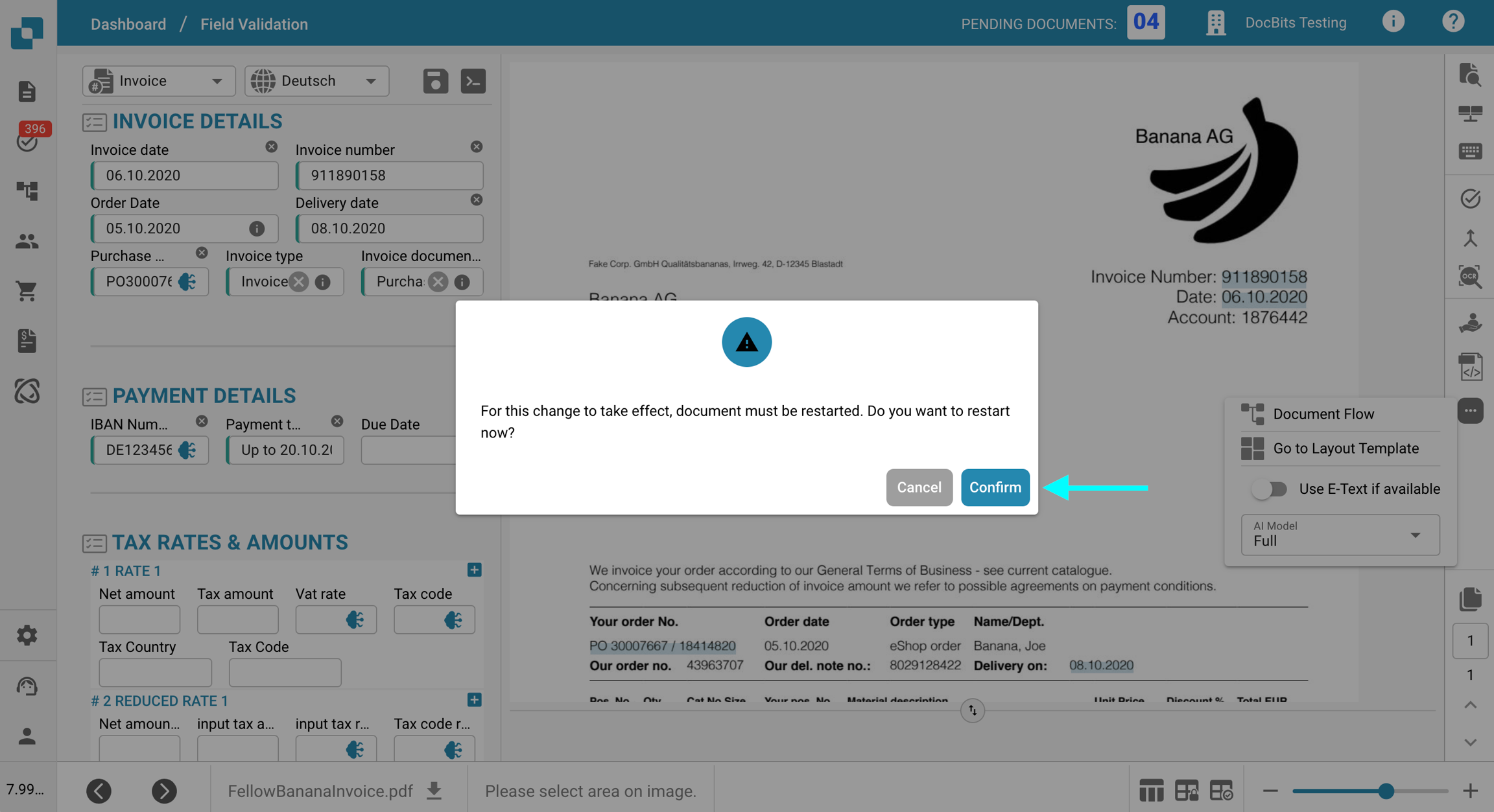
E-Text für die gesamte Organisation deaktivieren
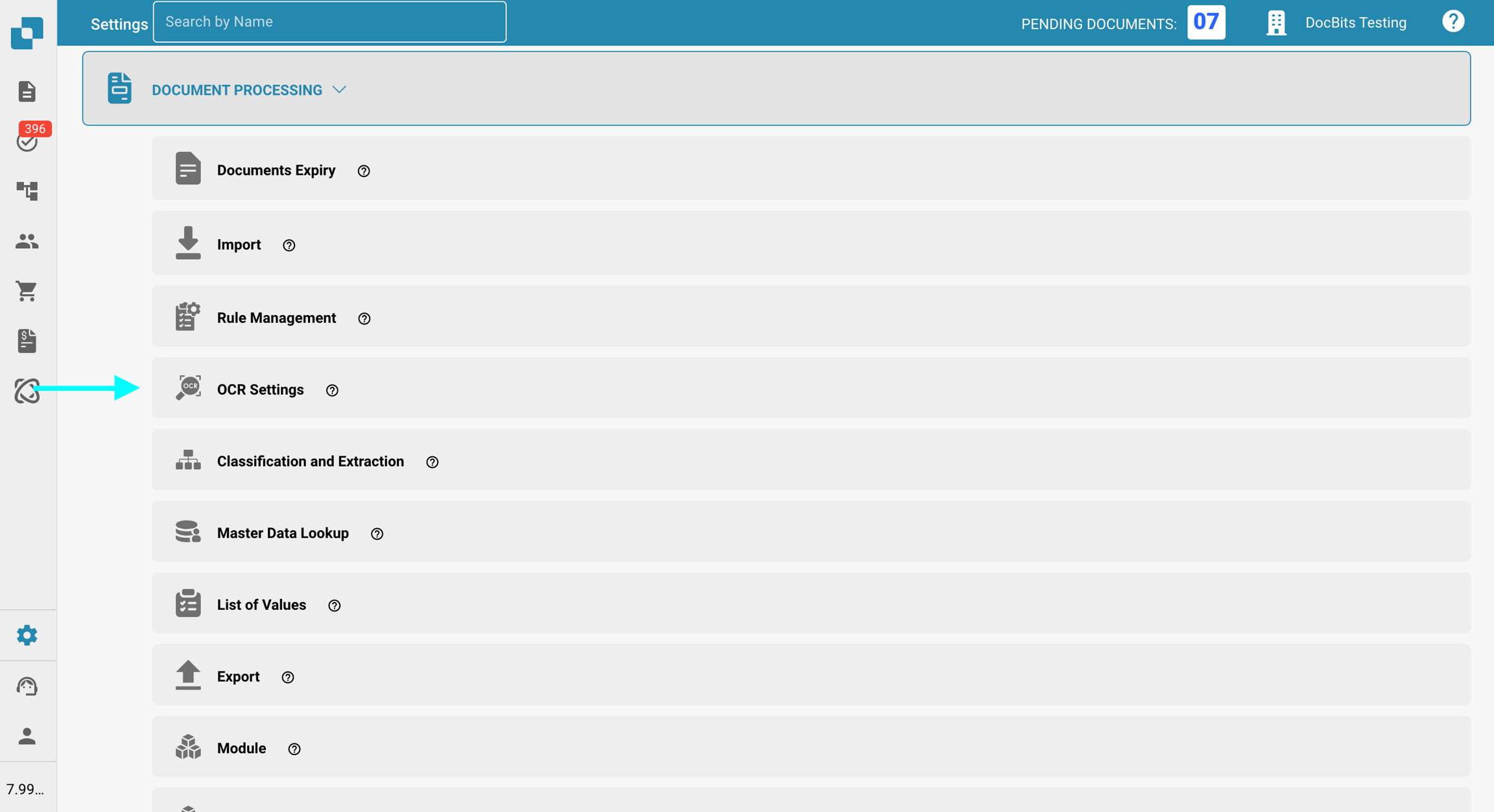
Gehen Sie zu Einstellungen → Verarbeitung von Dokumenten → OCR-Einstellungen.
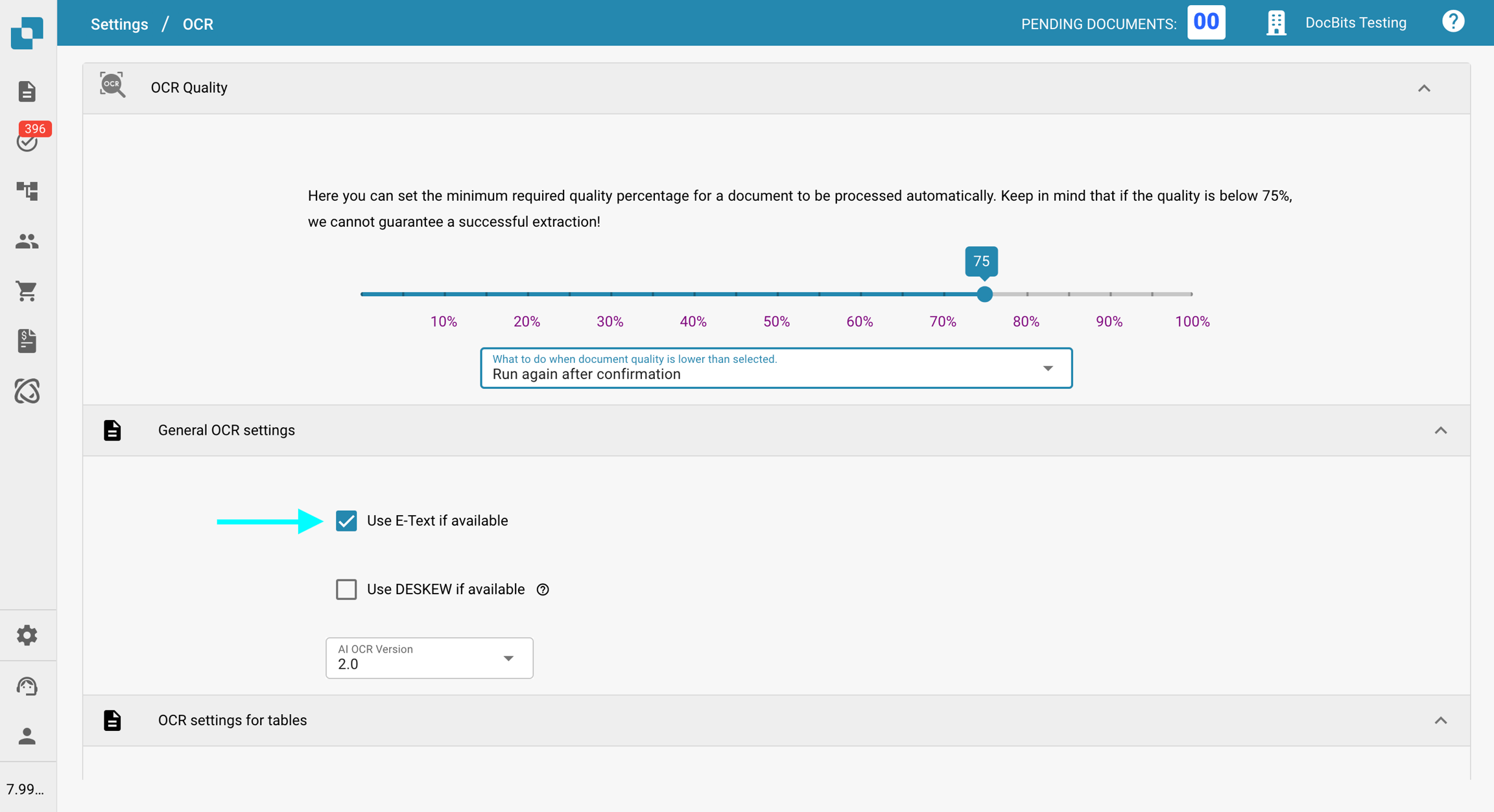
Deaktivieren Sie unter Allgemeine OCR-Einstellungen die Option E-Text verwenden, falls verfügbar.
Last updated
Was this helpful?