Brakujący tekst w ekstrakcji OCR
Problem
W niektórych przypadkach tekst może wydawać się brakujący w Widoku OCR, co uniemożliwia jego ekstrakcję za pomocą funkcji ekstrakcji.
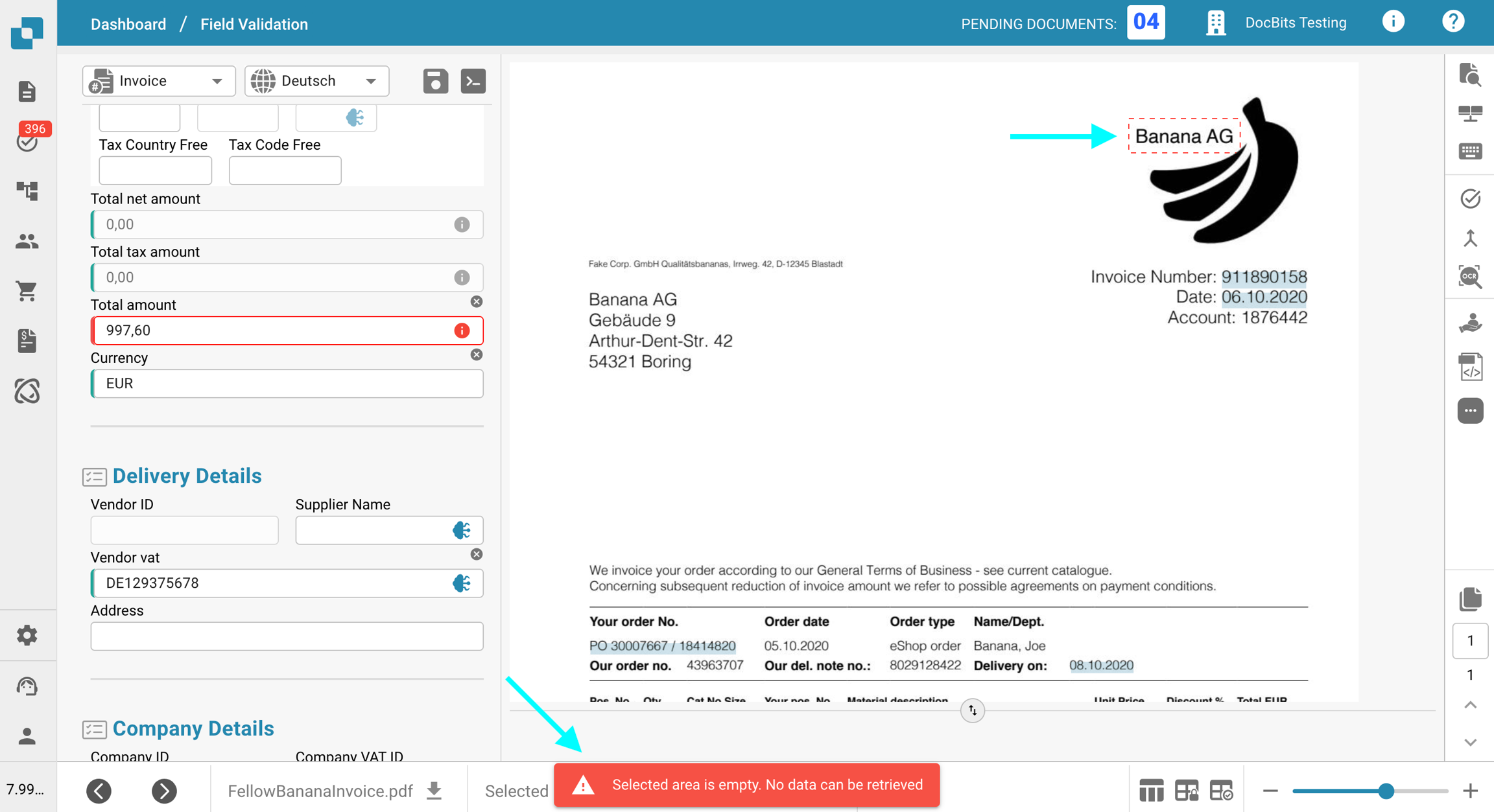
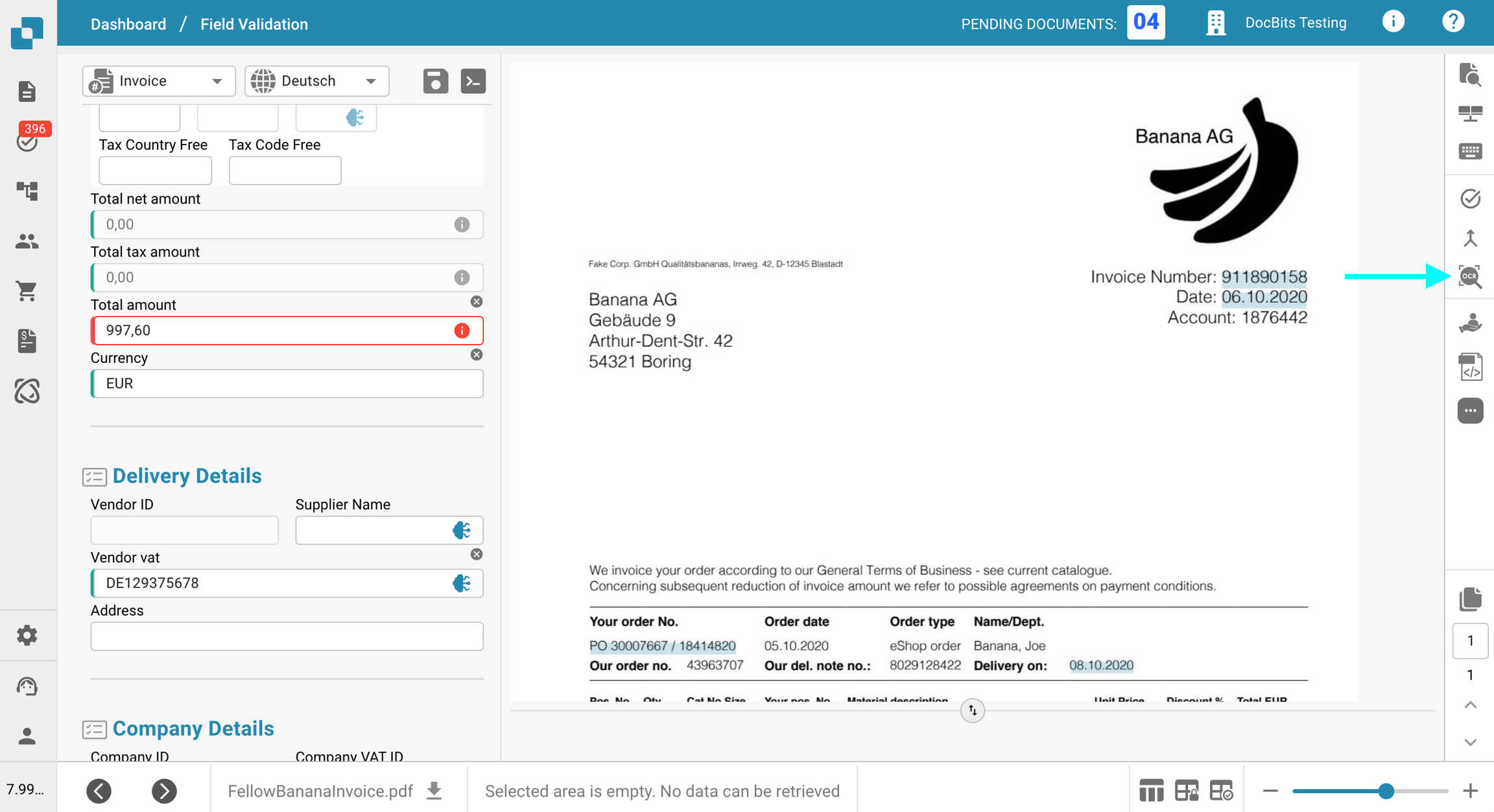
Aby to zweryfikować, kliknij przycisk Widok OCR na pasku narzędzi po prawej stronie. Jeśli tekst się tam nie pojawia, oznacza to, że nie jest dostępny do ekstrakcji.
Przyczyna
Najprawdopodobniej przyczyną jest to, że tekst, który próbujesz wyodrębnić, jest częścią obrazu (np. logo lub zeskanowany fragment) w dokumencie. Gdy funkcja E-Text jest włączona, tekst, który pojawia się na obrazach lub logo, nie jest uwzględniany w warstwie tekstu wyodrębnionego. W rezultacie ten tekst nie może być dostępny ani wyodrębniony za pomocą standardowej logiki ekstrakcji.
Rozwiązanie
Aby rozwiązać ten problem, wyłącz funkcję E-Text—dla konkretnego dostawcy lub dla całej organizacji. Po dezaktywowaniu E-Text, DocBits będzie polegać wyłącznie na OCR, który jest w stanie wyodrębnić tekst z obrazów i logo w dokumencie.
Wyłącz E-Text dla konkretnego dostawcy
Otwórz dokument od konkretnego dostawcy w Walidacji pól.
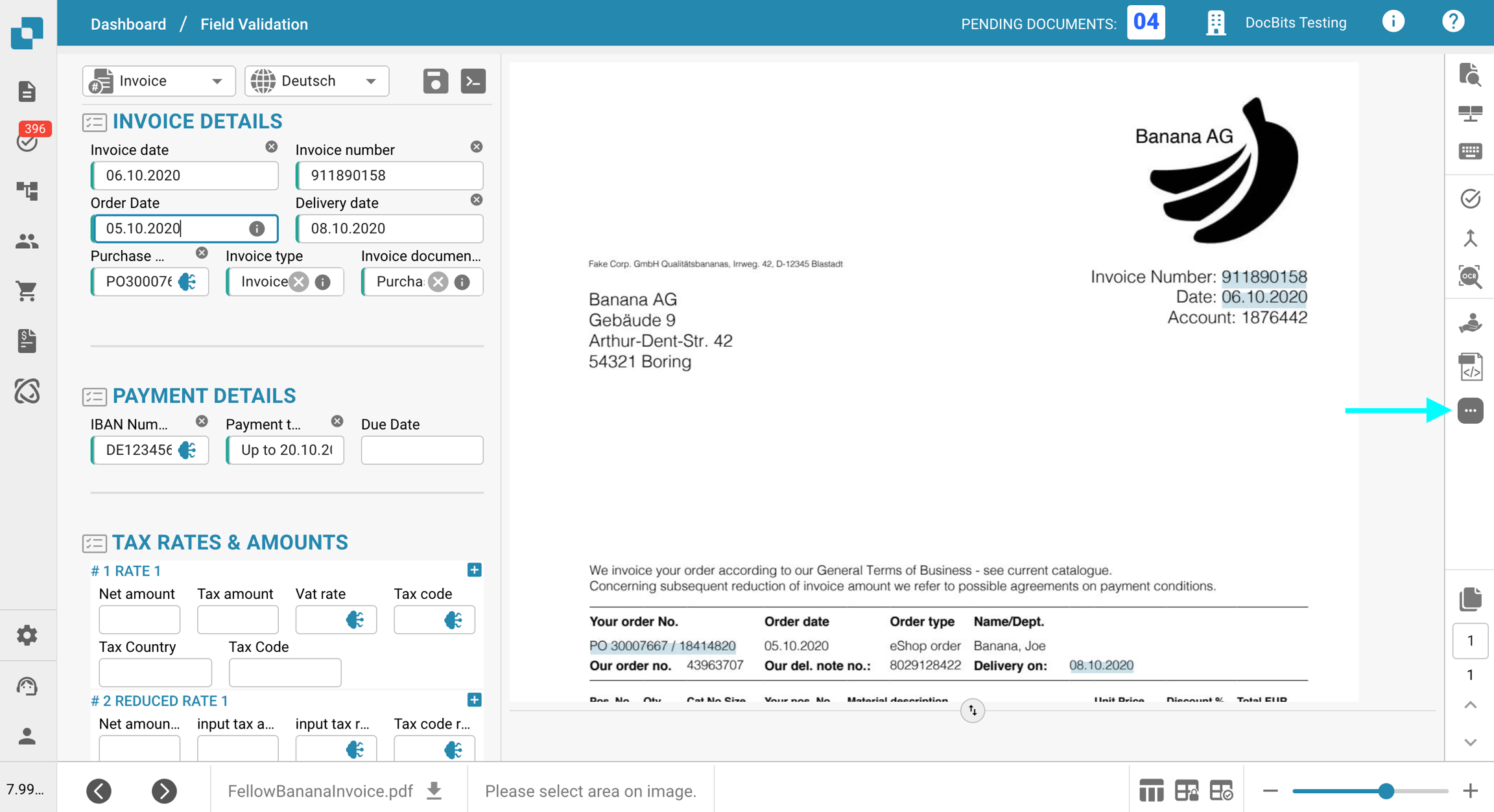
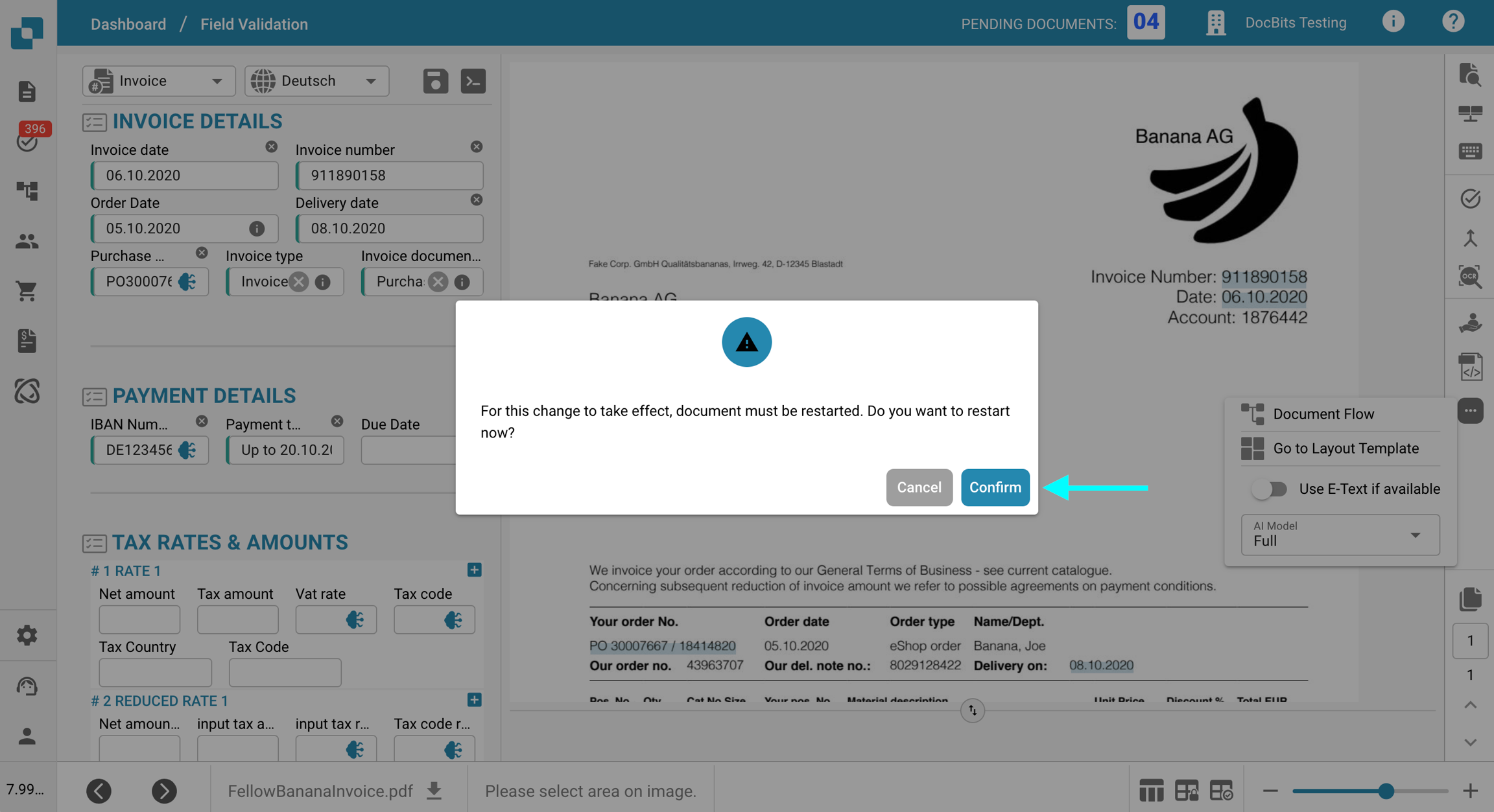
Kliknij menu z trzema kropkami na pasku narzędzi po prawej stronie.
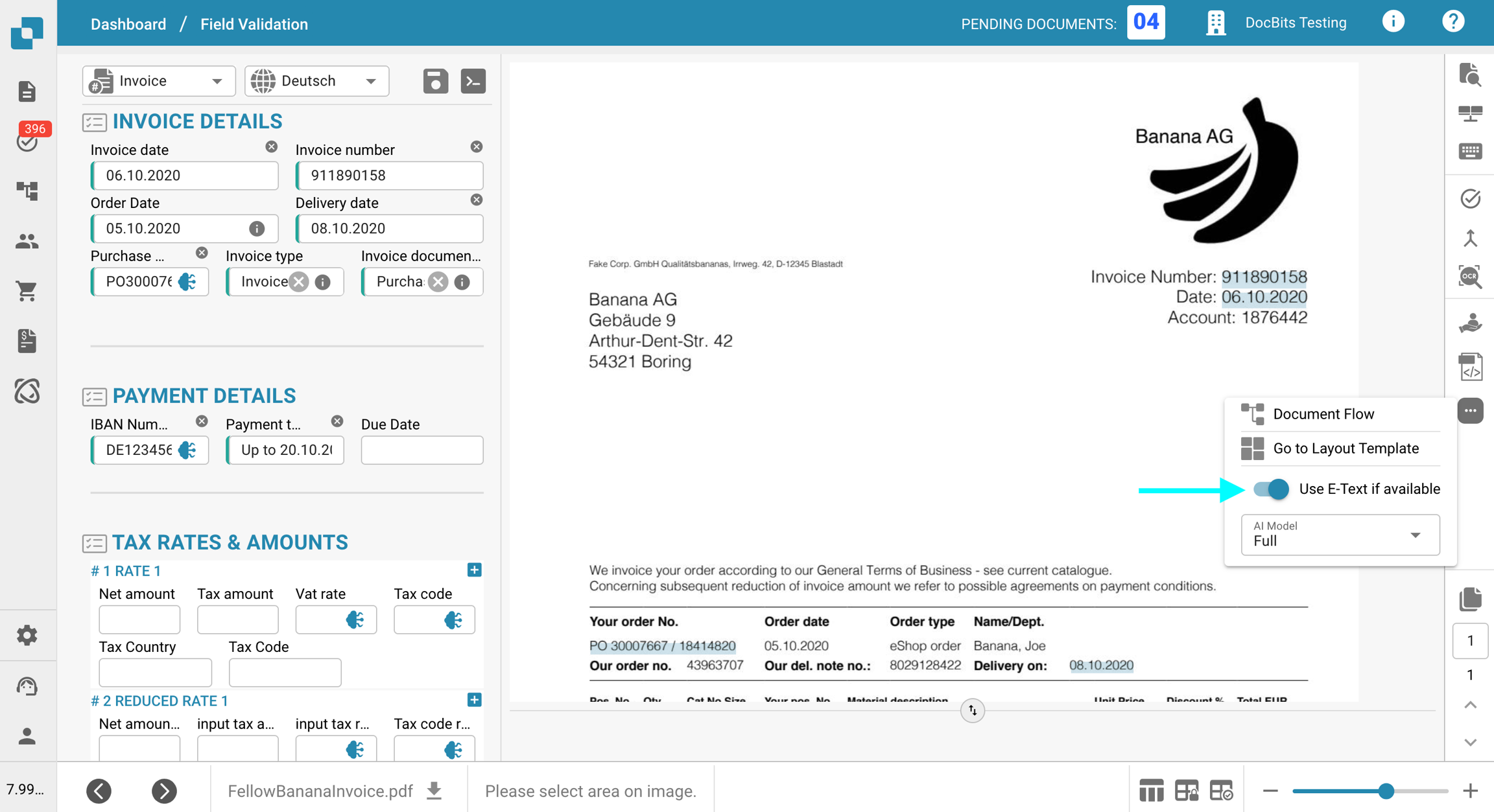
Odznacz Użyj E-Textu, jeśli jest dostępny.
Kliknij Potwierdzać, aby ponownie uruchomić przetwarzanie dokumentu.
Wyłącz E-Text dla całej organizacji
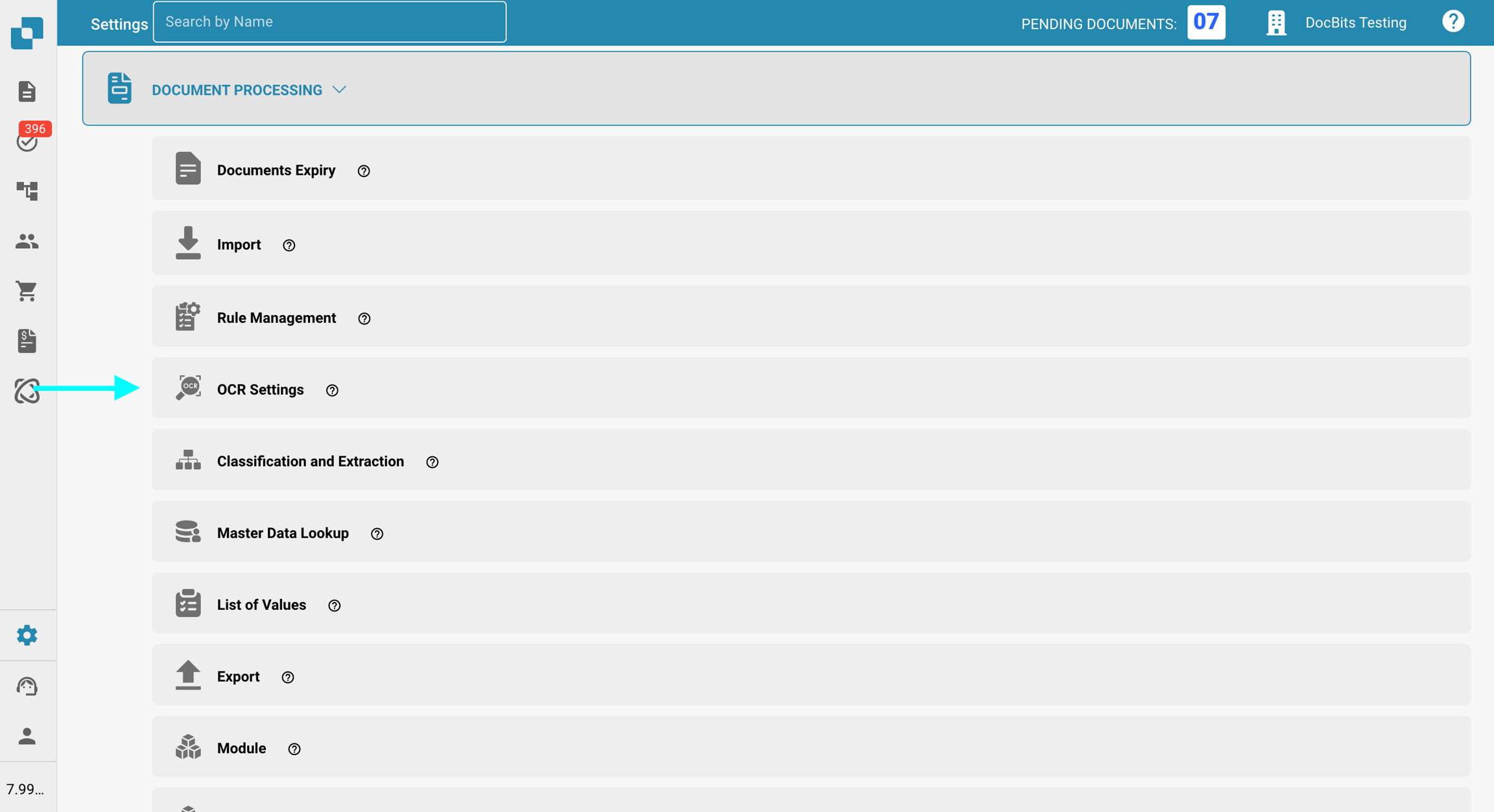
Przejdź do Ustawienia → Przetwarzanie dokumentów → Ustawienia OCR.
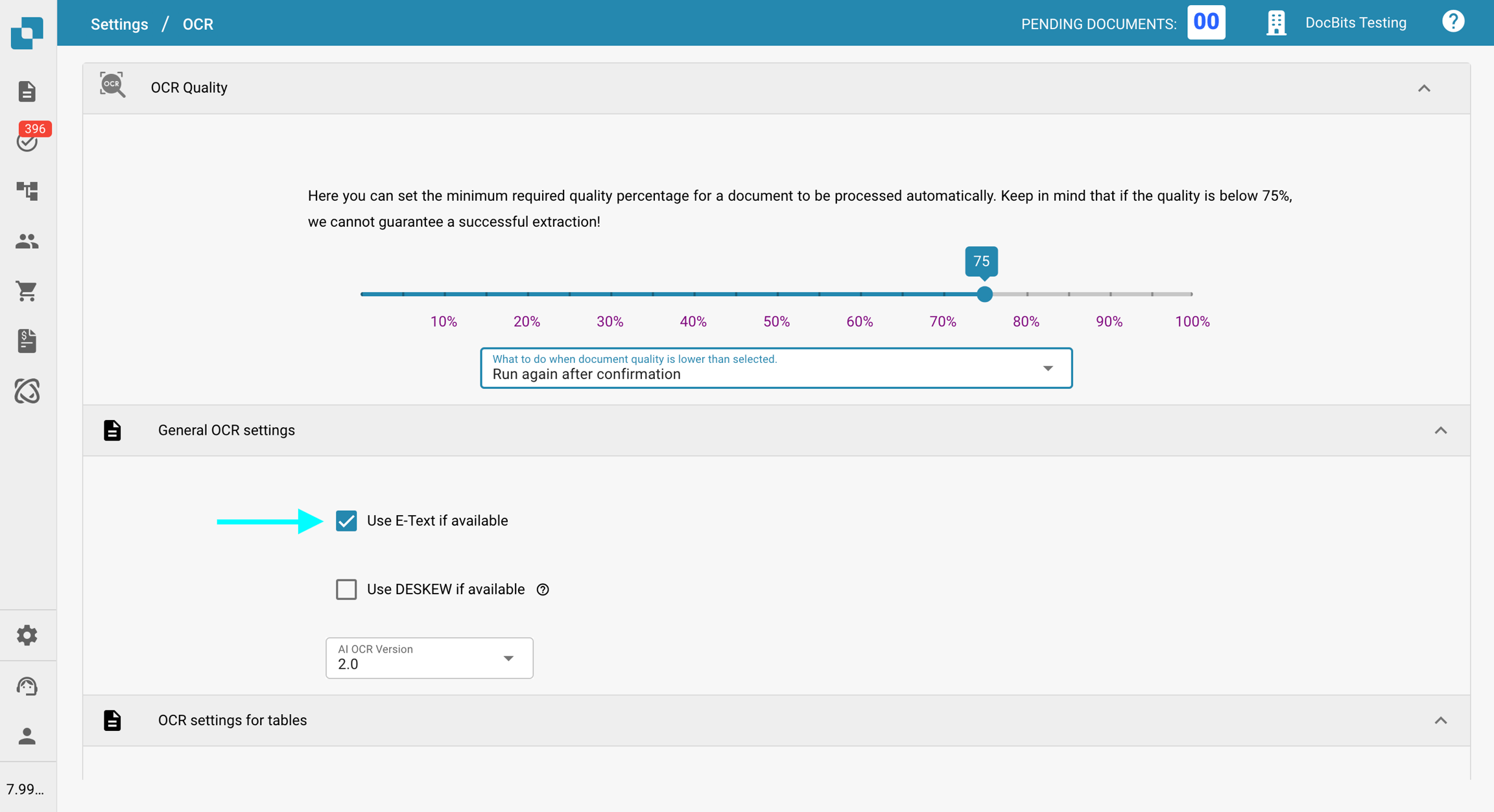
W sekcji Ogólne ustawienia OCR odznacz opcję Użyj E-Textu, jeśli jest dostępny.
Last updated
Was this helpful?