Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
To effectively manage training data, you can take the following steps:
Adding new records:
Collect new documents to serve as training data for your model.
Make sure these documents are a representative sample of the different types of data the model is designed to process.
Upload the new records to your training data repository.
Editing existing records:
Regularly review your existing training data and update it as needed. This may include editing document metadata, adding additional labels, or removing erroneous or non-representative records.
Removing records:
Identify outdated, inaccurate, or no longer relevant records and remove them from your training data set.
Make sure you have a clear process for deciding which records to remove and document that process.
Training data versioning:
Implement a version control system for your training data to track changes and keep a clear history of dataset changes. This allows you to restore older versions of the training data when needed and track changes.
Training data security:
Ensure your training data is appropriately protected, especially if it contains sensitive or confidential information. Implement access controls to ensure only authorized users can access the training data, and encrypt the data during transfer and storage.
Documentation and tracking:
Document all changes to your training data, including adding, editing, and removing datasets. This allows you to track the history of your training data and ensure you have current and relevant data for training your model.
By regularly managing and updating your training data, you can ensure that your model is trained with current and representative data and achieves optimal performance.
Here are some best practices for continuous model training:
Perform regular training:
Perform regular training cycles to ensure your model is up to date and adapts to changes in data and requirements.
The frequency of training can vary depending on the type of data and training progress, but it is important to train regularly to maintain model performance.
Use updated sample documents:
Use recent sample documents that are representative of the data your model will face.
This may include adding new documents, removing outdated documents, or editing metadata to ensure the training data is current and relevant.
Select diverse samples:
Make sure your training data covers a wide variety of scenarios and use cases to ensure the model is robust and versatile.
Consider different variations in layouts, languages, formats, and content to ensure the model works well in different situations.
Monitor model performance:
Regularly monitor the performance of the model using relevant metrics such as accuracy, precision, and recall.
Analyze the results of classification tests and validation checks to identify weak points and spot opportunities for improvement.
Incorporate continuous feedback:
Incorporate feedback from users and experts to continuously improve the model.
Collect feedback on misclassifications or inadequate results and use this information to adjust and optimize the model.
Automate the training process:
Automate the training process to increase efficiency and minimize human error.
Use tools and scripts to automatically perform model training, evaluation, and updating when new data is available or changes are required.
By implementing these best practices for continuous model training, you can ensure that your model is constantly improving and achieving optimal performance to meet the needs of your use case.
To test the trained model and evaluate its accuracy and operational readiness, you can follow the steps below:
Preparing the test data:
Collect a representative sample of test data covering different types of documents and scenarios that the model will handle in the field. Ensure that the test data is of high quality and correctly labeled.
Running the classification tests:
Run the classification tests on the prepared test data.
Feed the test data into the model and let the model make predictions for classifying the documents.
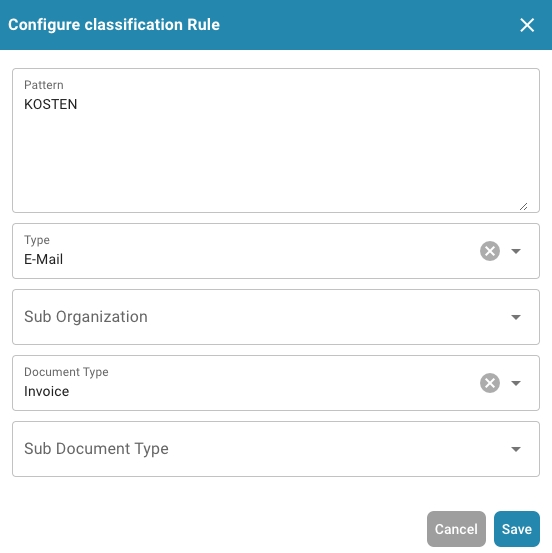
Add a new one or edit an existing classification rule.
Evaluating the model accuracy:
Compare the model's predictions with the actual classifications of the test data. Calculate metrics such as accuracy, precision, recall, and F1 score to evaluate the model's performance. These metrics provide insight into how well the model classified the documents and how reliable it is.
Analyze errors:
Examine the errors the model made when classifying the test data and analyze their causes. Identify patterns or trends in the errors and, if necessary, make adjustments to the model to improve its performance.
Optimize the model:
Based on the results of the classification tests and error analysis, you can optimize the model by adding training data, adjusting training parameters, or changing the model architecture. Repeat the testing process to check if the optimizations improved the model's performance.
Document the results:
Document the results of the classification tests and any adjustments or optimizations made to the model. This will help you track the model's progress over time and ensure that it is constantly improving.
By regularly running classification tests and evaluating the performance of your model, you can ensure that it is suitable for use in production and delivers accurate results.
Provide detailed instructions on how to import sample documents for training, including the format and document types to use.
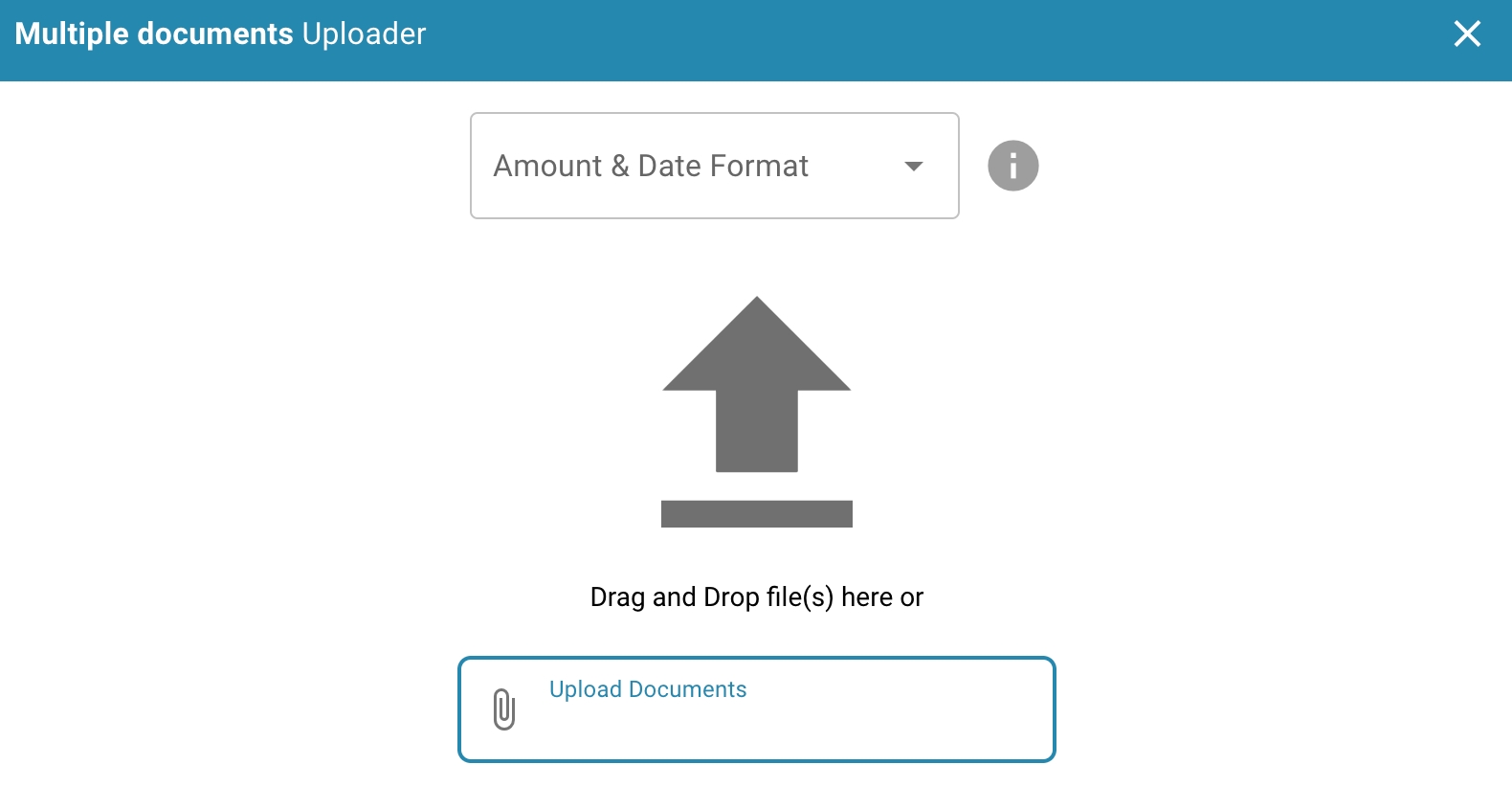
To import sample documents for training, follow these steps:
Prepare the sample documents: Make sure the sample documents are in a supported format, such as PDF, Word, Excel, etc. These documents should cover a variety of types and formats that may be encountered in production operations of the document processing system.
Navigate to the import function: Log in to the administration area of the document processing system and navigate to the area where you can import new documents.
Select the option to import documents: Click the button or link to import documents. There may be an option such as "Import".
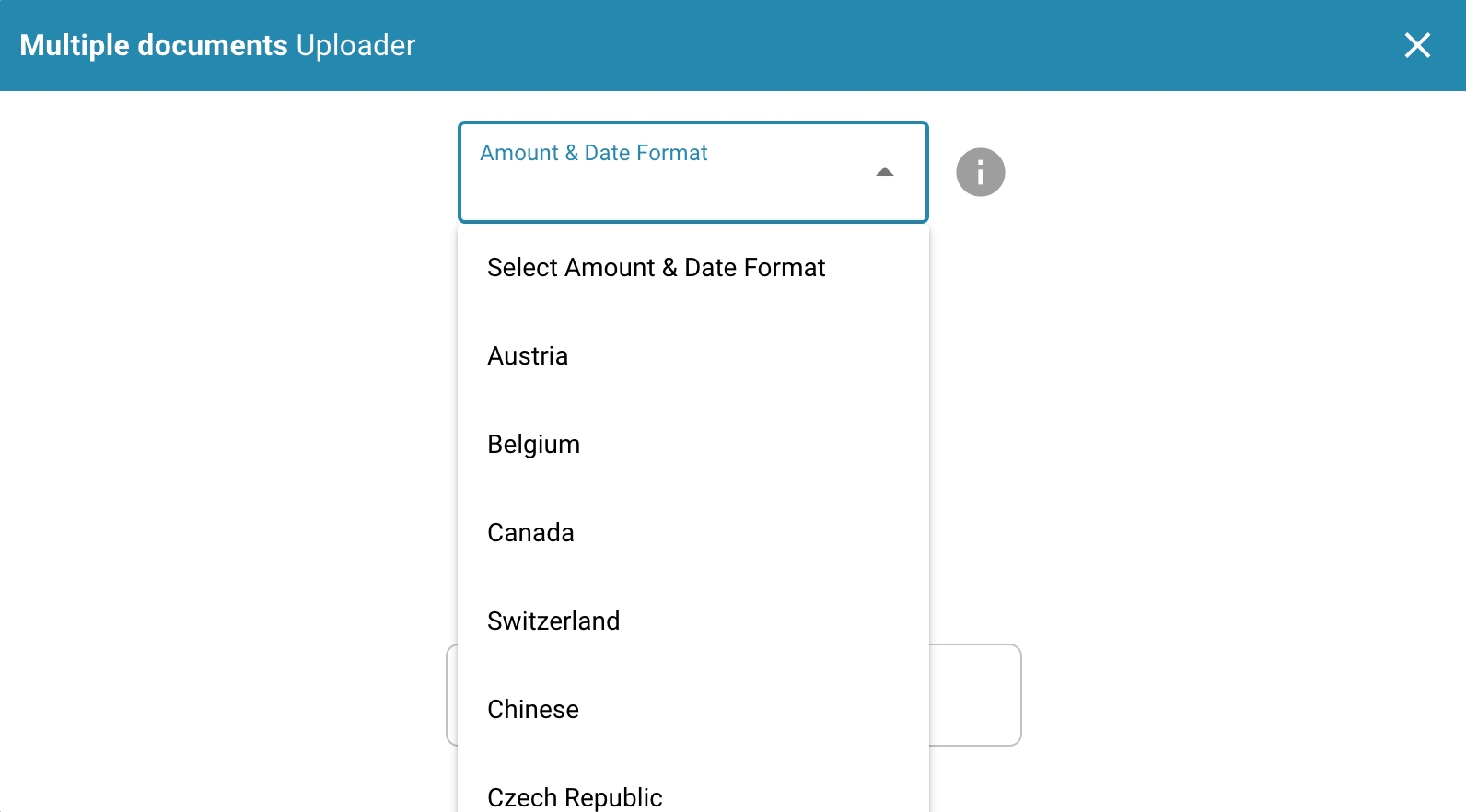
Select amount & date format:
Amount Format:
The amount format may vary by region, but in general there are some common conventions:
Currency symbol: The currency symbol is usually provided before the amount, e.g. "$" for US dollars, "€" for euros, "£" for British pounds, etc.
Thousands separator: In some countries, long numbers are separated by a thousand separator for better readability. In the US, a comma is commonly used (e.g. 1,000), while in many European countries a period is used (e.g. 1,000).
Decimal separator: The decimal separator is used to separate the integer part from the decimal places. Most English-speaking countries use a period (e.g. 10.99), while many European countries use a comma (e.g. 10.99).
The date format also varies by region, with different countries having different conventions. Here are the most common formats:
Day-Month-Year (DD-MM-YY or DD.MM.YY): In many European countries, the date is specified in day-month-year format. For example, "21.05.24" represents May 21, 2024.
Month-Day-Year (MM-DD-YY or MM/DD/YY): In the United States, the month-day-year format is often used. For example, "05/21/24" represents May 21, 2024.
Year-Month-Day (YY-MM-DD or YY/MM/DD): In some other countries, the year-month-day format is preferred. For example, "24/05/21" represents May 21, 2024.
It is important to note the specific format to avoid misunderstandings, especially in international communications or financial transactions.
Select the sample documents: Select the sample documents you want to import. This can be done by uploading the files from your local computer or by selecting documents from an already connected location.
Configure the document types and subtypes (if required): If your system supports different document types or subtypes, assign the appropriate type to each imported document. This will help the system to categorize and process the documents correctly.
Start the import process: Confirm the selection of documents and start the import process. Depending on the size and number of documents, this process may take some time.
Check the import status: Check the status of the import process to make sure that all documents were imported successfully. Make sure that no errors occurred and that the documents were processed correctly.
Train the model: After the documents are imported, use them to train the document processing system model. Perform training according to the system's instructions to make sure it can process the sample data effectively.
By regularly adding sample documents for training, you can ensure that your document processing system is always up to date and provides accurate and efficient processing.
Regular model training is critical to ensure that a document processing system continues to work effectively and accurately as document formats and content change.
Here are some key reasons for regular model training:
Adaptation to new formats:
Documents are often created in different formats, be it PDF, Word, Excel, or others.
New versions of these formats may have additional features or changes in formatting that the processing system may not recognize unless it is updated accordingly.
By regularly training the model, the system can adapt to these new formats to ensure smooth processing.
Adaptation to changing content:
The content of documents can change over time, be it due to updates to business processes, changes in policies, or new industry standards.
Regular training allows the processing system to adapt to these changes and continue to deliver accurate results.
Optimizing accuracy:
By training the model with new data, algorithms and models can be continuously improved to increase the accuracy of document processing.
This is especially important in areas where precision and reliability are critical, such as processing financial documents or medical records.
Handling exceptions:
Regular model training allows the system to better identify and handle exceptions and boundary conditions.
This can help reduce errors and improve overall system performance.
Ensuring compliance:
In industries with strict compliance requirements, it is important that the document processing system is always up to date to meet legal requirements.
Regular training and updating of the model can help ensure the system complies with current standards.
Overall, regular model training is an essential component to the effectiveness and reliability of a document processing system. It allows the system to continuously adapt to changing requirements and deliver accurate results, which in turn improves efficiency and productivity.
Here are solutions to some typical problems that can arise during model training:
Data format errors:
Make sure the training data is in the correct format and meets the model's requirements.
Check the data for missing values, incorrect encodings, or unexpected structures.
If necessary, convert the data to the correct format and perform preprocessing to ensure it is suitable for training.
Training model convergence issues:
If the model is struggling to converge or show consistent improvements, check the hyperparameters and training configurations.
Experiment with different learning rates, batch sizes, or optimization algorithms to facilitate convergence.
If necessary, reduce the model complexity or increase the amount of training data to improve model performance.
Unexpected model performance degradation:
If the model shows unexpectedly poor performance after training, check the training data for possible errors or inaccuracies.
Analyze the error patterns and check if certain classes or features are classified poorly.
Run further tests with new training data to ensure that the model is consistent and reliable.
Overfitting or underfitting:
Monitor model performance for overfitting or underfitting, which can lead to poor generalization ability.
Experiment with regularization techniques such as L2 regularization or dropout to reduce overfitting.
Increase the amount of training data or data variation to avoid underfitting and improve model performance.
Lack of representativeness of training data:
Make sure your training data covers a sufficient variety of scenarios and use cases to prepare the model for different situations.
If necessary, supplement the training data with additional examples or synthetic data to improve coverage and increase model performance.
By identifying and fixing these issues specifically, you can improve the performance of your model and ensure that it works effectively and reliably to meet the needs of your use case.
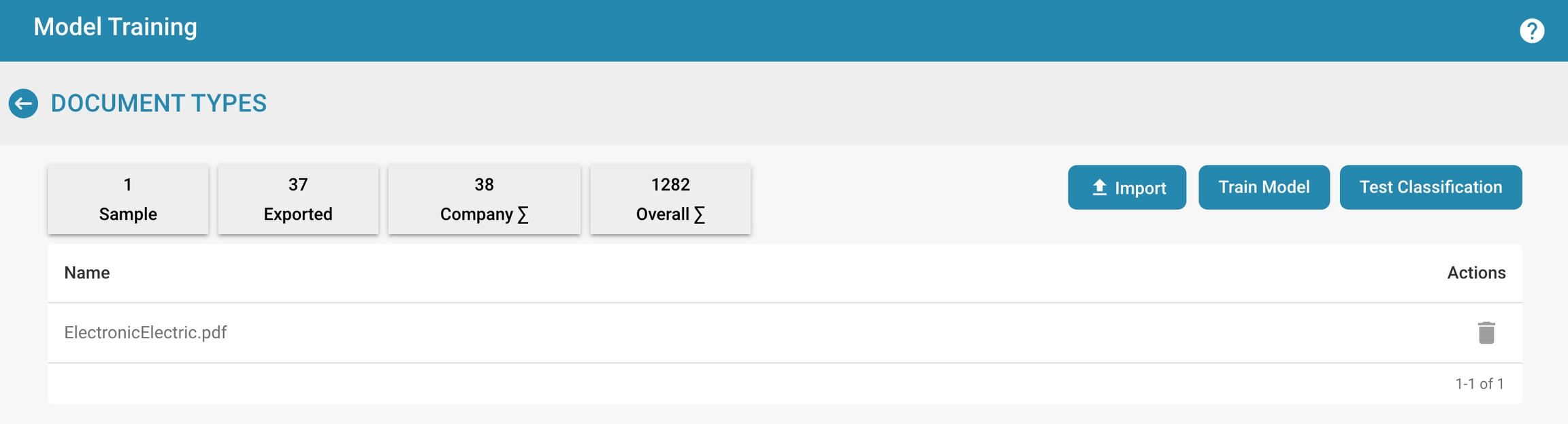
Modeltraining stelt beheerders in staat om het trainen van machine learning-modellen die specifiek zijn voor elk documenttype te overzien en te beheren. Door een gestructureerde interface te bieden voor het importeren van voorbeeldgegevens, het trainen van modellen en het testen van hun prestaties, zorgt Docbits ervoor dat de gegevensextractiecapaciteiten in de loop van de tijd continu verbeteren.
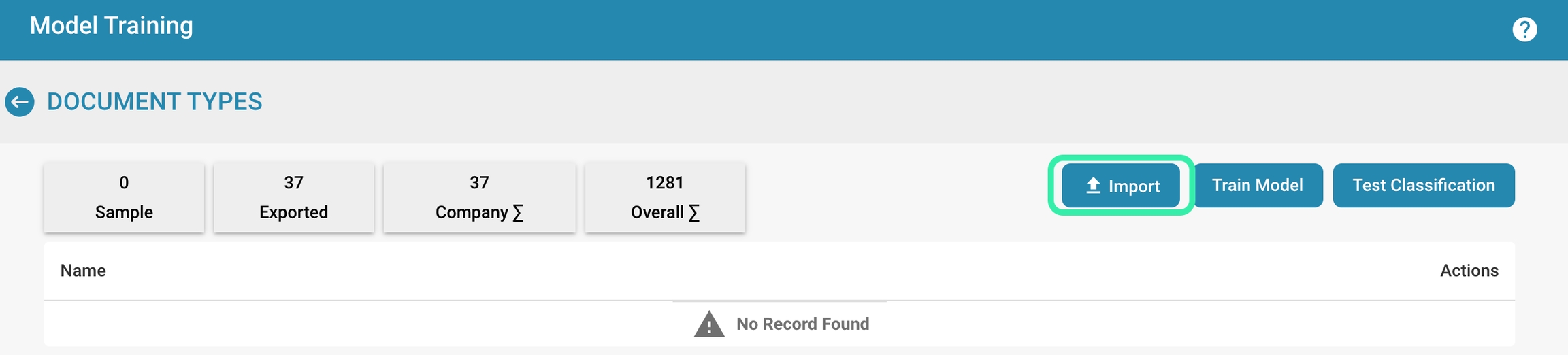
Metrics Overzicht:
Voorbeeld: Aantal voorbeelddocumenten dat is gebruikt voor training.
Geëxporteerd: Aantal documenten dat succesvol is geëxporteerd na verwerking.
Bedrijf Σ: Totaal aantal bedrijfsspecifieke documenten dat is verwerkt.
Totaal Σ: Totaal aantal documenten dat is verwerkt over alle categorieën.
Trainings- en Testopties:
Importeren: Stelt beheerders in staat om nieuwe trainingsdatasets te importeren, die doorgaans gestructureerde voorbeelden zijn van documenten die door het systeem herkend moeten worden.
Model Trainen: Start het trainingsproces met behulp van de geïmporteerde gegevens om de herkennings- en extractiecapaciteiten van het systeem te verbeteren.
Testclassificatie: Maakt het mogelijk om het model te testen om de prestaties bij het classificeren en extraheren van gegevens uit nieuwe of ongeziene documenten te evalueren.
Actieknoppen:
Veld Aanmaken: Voeg nieuwe gegevensvelden toe die het model moet herkennen en extraheren.
Acties: Deze dropdown kan opties bevatten zoals details bekijken, configuraties bewerken of trainingsgegevens verwijderen.